# a VERY basic list of named elements
car_list <- list(manufacturer = "Honda", vehicle = "Civic", year = 2020)Finding JSON Sources
I’ve covered some strategies for parsing JSON with a few methods in base R and/or tidyverse in a previous blog post. I’d like to go one step up in the chain, and talk about pulling raw data/JSON from sites. While having a direct link to JSON is common, in some situations where you’re scraping JavaScript fed by APIs the raw data source is not always as easy to find.
I have three examples for today:
- FiveThirtyEight 2020 NFL Predictions
- ESPN Win Percentage/play-by-play (embedded JSON)
- ESPN Public API
Web vs Analysis
Most of these JSON data sources are intended to be used with JavaScript methods, and have not been oriented to a “flat” data style. This means the JSON has lots of separations of the data for a specific use/purpose inside the site, and efficient singular representations of each data in JSON storage as opposed to normalized data with repeats in a dataframe. While extreme detail is out of scope for this blogpost, JSON is structured as a “collection of name/value pairs” or a “an ordered list of values”. This means it is typically represented in R as repeated lists of list elements, where the list elements can be named lists, vectors, dataframes, or character strings.
Alternatively typically data for analysis is usually most useful as a normalized rectangle eg a dataframe/tibble. “Under the hood a data frame is a list of equal length vectors” per Advanced R.
One step further is tidy data which is essentially “3rd normal form”. Hadley goes into more detail in his “Tidy Data” publication. The takeaway here is that web designers are optimizing for their extremely focused interactive JavaScript apps and websites, as opposed to novel analyses that we often want to work with. This is often why there are quite a few steps to “rectangle” a JSON.
An aside on Subsetting
Subsetting in R is done many different ways, and Hadley Wickham has an entire chapter dedicated to this in Advanced R. It’s worth reading through that chapter to better understand the nuance, but I’ll provide a very brief summary of the options.
“Subsetting a list works in the same way as subsetting an atomic vector. Using
[always returns a list;[[and$, … let you pull out elements of a list.”
When working with lists, you can typically use $ and [[ interchangeably to extract single list elements by name. [[ requires exact matching whereas $ allows for partial matching, so I typically prefer to use [[. To extract by location from base R you need to use [[.
purrrfunctionspluck()andchuck()implement a generalised form of[[that allow you to index deeply and flexibly into data structures.pluck()consistently returnsNULLwhen an element does not exist,chuck()always throws an error in that case.”
So in short, you can use $, [[ and pluck/chuck in many of the same ways. I’ll compare all the base R and purrr versions below (all should return “Honda”).
# $ subsets by name
car_list$manufacturer[1] "Honda"# notice partial match
car_list$man[1] "Honda"# [[ requires exact match or position
car_list[["manufacturer"]][1] "Honda"car_list[[1]][1] "Honda"# pluck and chuck provide a more strict version of [[
# and can subset by exact name or position
purrr::pluck(car_list, "manufacturer")[1] "Honda"purrr::pluck(car_list, 1)[1] "Honda"purrr::chuck(car_list, "manufacturer")[1] "Honda"purrr::chuck(car_list, 1)[1] "Honda"For one more warning of partial name matching with $, where we now have a case of two elements with similar names see below:
car_list2 <- list(manufacturer = "Honda", vehicle = "Civic", manufactured_year = 2020)
# partial match throws a null
car_list2$manNULL# exact name returns actual elements
car_list2$manufacturer[1] "Honda"An aside on JavaScript
If we dramatically oversimplify JavaScript or their R-based counterparts htmlwidgets, they are a combination of some type of JSON data and then functions to display or interact with that data.
We can quickly show a htmlwidget example via the fantastic reactable R package.
That gives us the power of JavaScript in R! However, what’s going on with this function behind the scenes? We can extract the dataframe that has now been represented as a JSON file from the htmlwidget!
table_data <- table_ex[["x"]][["tag"]][["attribs"]][["data"]]
table_data %>% class()[1] "json"This basic idea, that the data is embedded as JSON to fill the JavaScript app can be further applied to web-based apps! We can use a similar idea to scrape raw JSON or query a web API that returns JSON from a site.
FiveThirtyEight
FiveThirtyEight publishes their ELO ratings and playoff predictions for the NFL via a table at projects.fivethirtyeight.com/2020-nfl-predictions/. They are also kind enough to post this data as a download publicly! However, let’s see if we can “find” the data source feeding the JavaScript table.
rvest
We can try our classical rvest based approach to scrape the HTML content and get back a table. However, the side effect of this is we’re returning the literal data with units, some combined columns, and other formatting. You’ll notice that all the columns show up as character and this introduces a lot of other work we’d have to do to “clean” the data.
library(xml2)
library(rvest)
url_538 <- "https://projects.fivethirtyeight.com/2020-nfl-predictions/"
raw_538_html <- read_html(url_538)
raw_538_table <- raw_538_html %>%
html_node("#standings-table") %>%
html_table(fill = TRUE) %>%
janitor::clean_names() %>%
tibble()
raw_538_table %>% glimpse()Rows: 36
Columns: 12
$ x <chr> "", "", "", "elo with top qbelo rating", "1734", "17…
$ x_2 <chr> "", "", "", "1-week change", "+34", "", "", "", "", …
$ x_3 <chr> "", "", "", "current qb adj.", "", "", "", "", "", "…
$ x_4 <chr> "", "playoff chances", "", "", "", "", "", "", "", "…
$ x_5 <chr> "playoff chances", "playoff chances", "", "team", "B…
$ x_6 <chr> "playoff chances", "playoff chances", "", "division"…
$ playoff_chances <chr> "playoff chances", "playoff chances", "", "make div.…
$ playoff_chances_2 <chr> "playoff chances", NA, "", "make conf. champ", "✓", …
$ playoff_chances_3 <chr> NA, NA, "", "make super bowl", "✓", "✓", "—", "—", "…
$ playoff_chances_4 <chr> NA, NA, "", "win super bowl", "✓", "—", "—", "—", "—…
$ x_7 <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, …
$ x_8 <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, …Inspect + Network
Alternatively, we can Right Click + inspect the site, go to the Network tab, reload the site and see what sources are loaded. Again, FiveThirtyEight is very kind and essentially just loads the JSON as data.json.
I have screenshots below of each item, and the below is a short video of the entire process.
We can click over to the Network Tab after inspecting the site
We need to reload the web page to find sources
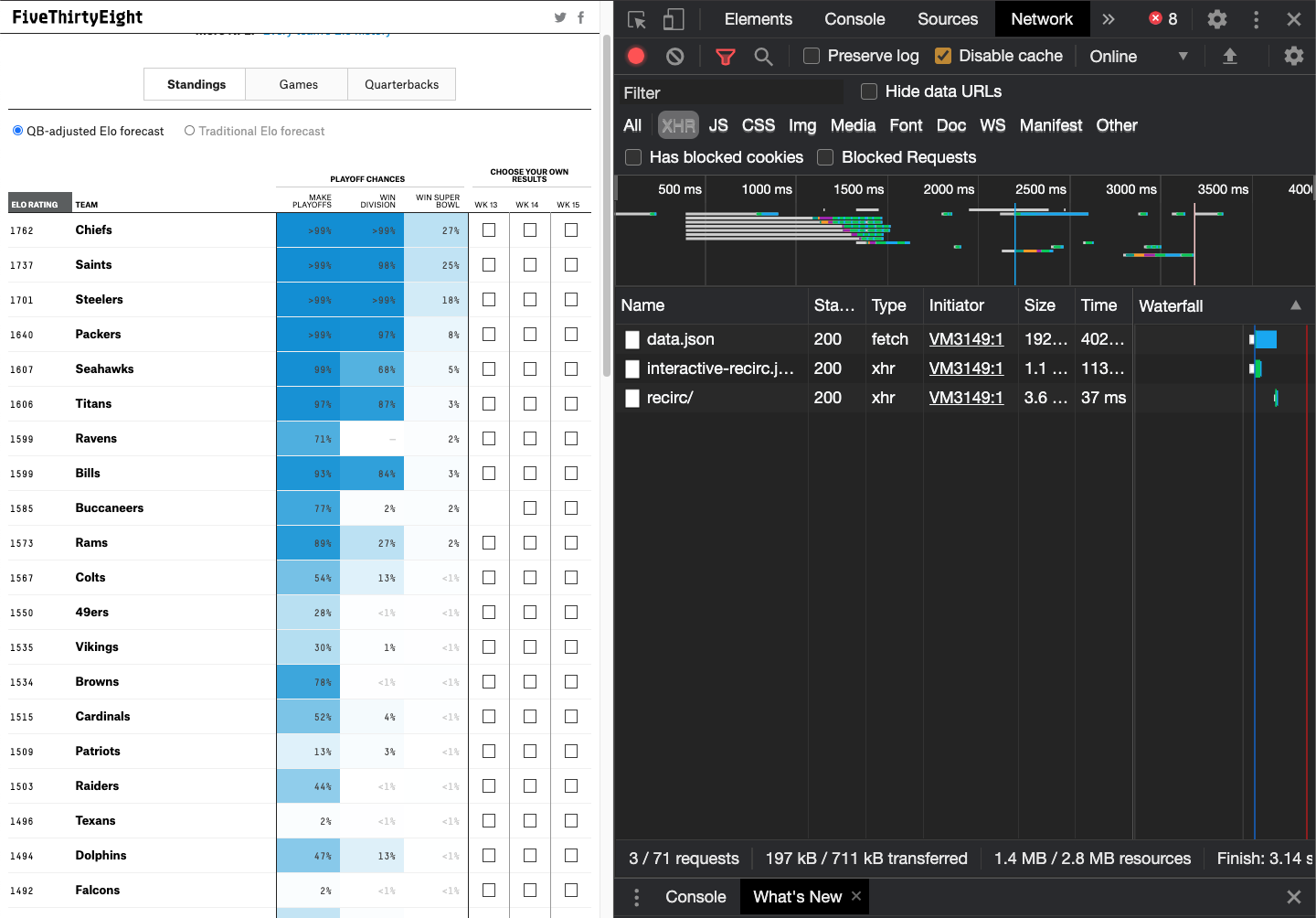
We can examine specific elements by clicking on them, which then shows us JSON!
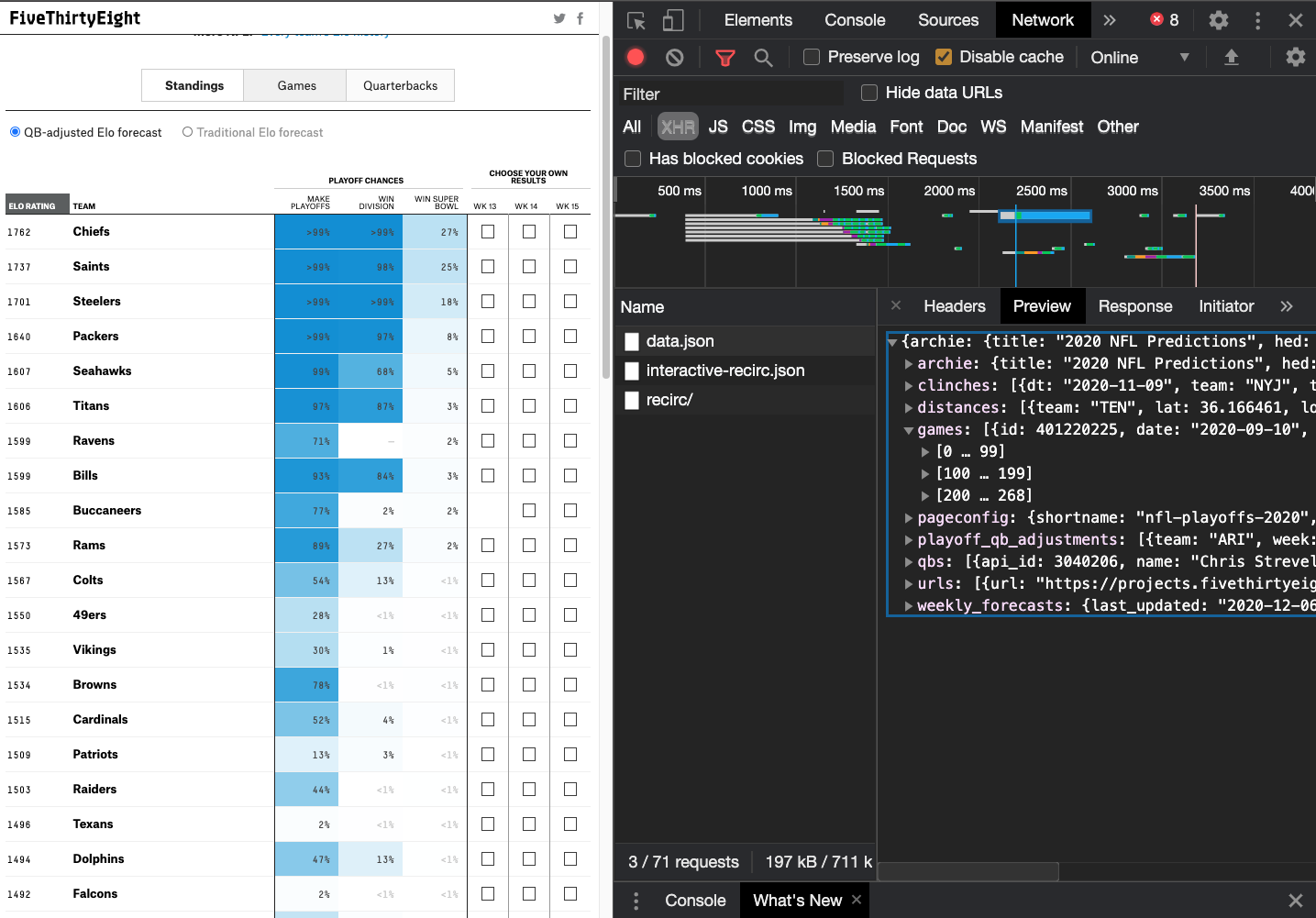
In our browser inspect, we can see the structure, and that it has some info about games, QBs, and forecasts. This looks like the right dataset! You can right click on data.json and open it in a new page. The url is https://projects.fivethirtyeight.com/2020-nfl-predictions/data.json, and note that we can adjust the year to get older or current data. So https://projects.fivethirtyeight.com/2019-nfl-predictions/data.json returns the data for 2019, and you can go all the way back to 2016! 2015 also exists, but with a different JSON structure, and AFAIK they don’t have data before 2015.
Read the JSON
Now that we have a JSON source, we can read it into R with jsonlite. By using the RStudio viewer or listviewer::jsonedit() we can take a look at what the overall structure of the JSON.
library(jsonlite)
raw_538_json <- fromJSON("https://projects.fivethirtyeight.com/2020-nfl-predictions/data.json", simplifyVector = FALSE)
raw_538_json %>% str(max.level = 1)List of 9
$ archie :List of 24
$ clinches :List of 114
$ distances :List of 32
$ games :List of 269
$ pageconfig :List of 20
$ playoff_qb_adjustments:List of 32
$ qbs :List of 87
$ urls :List of 2
$ weekly_forecasts :List of 2Don’t forget that the RStudio Viewer also gives you the ability to export the base R code to access a specific component of the JSON!
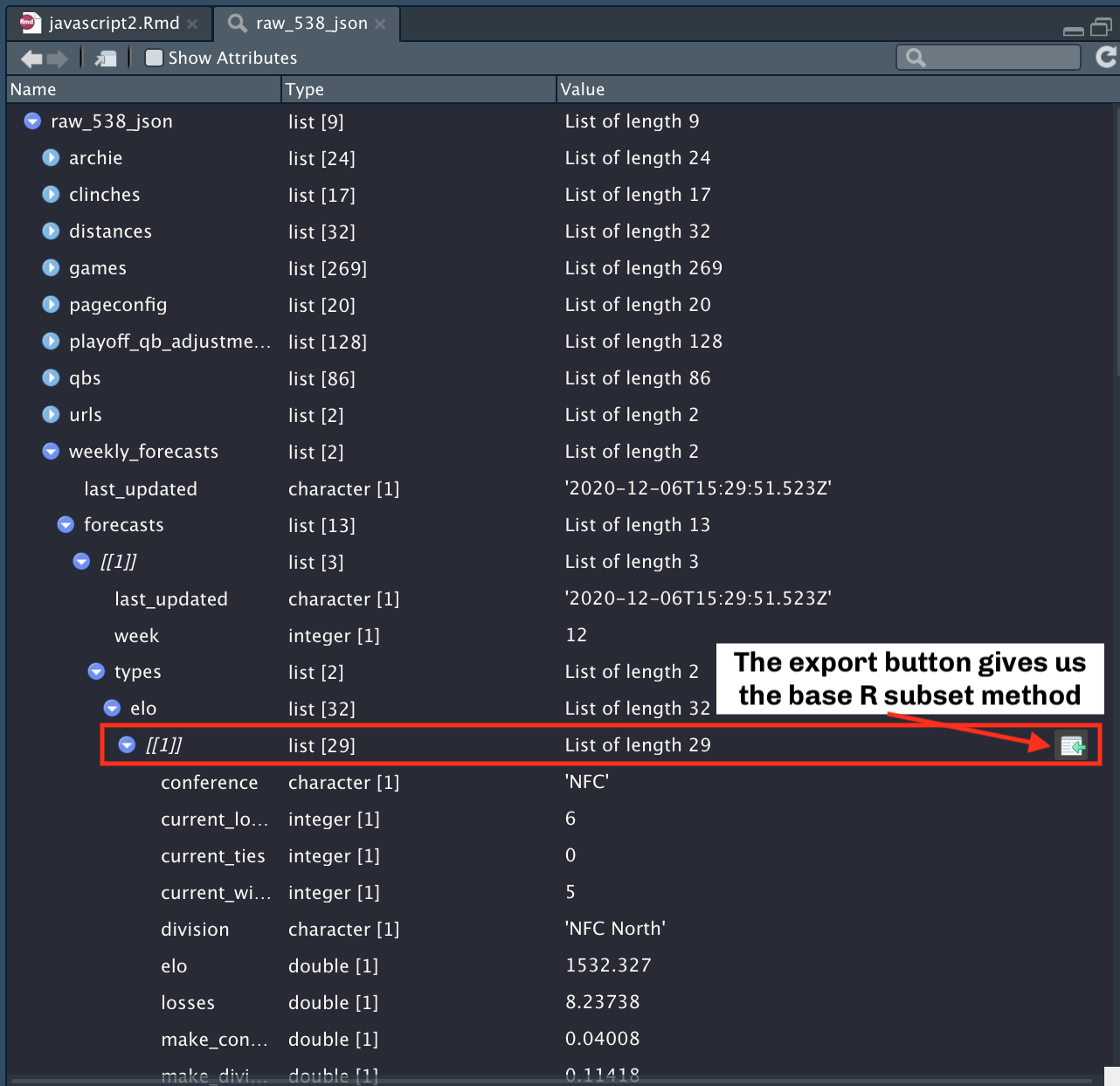
Which gives us the following code:
raw_538_json[["weekly_forecasts"]][["forecasts"]][[1]][["types"]][["elo"]][[1]]
ex_538_data <- raw_538_json[["weekly_forecasts"]][["forecasts"]][[1]][["types"]][["elo"]][[1]]
ex_538_data %>% str()List of 29
$ conference : chr "NFC"
$ current_losses : int 9
$ current_ties : int 0
$ current_wins : int 7
$ division : chr "NFC North"
$ elo : num 1489
$ losses : int 9
$ make_conference_champ: int 0
$ make_divisional_round: int 0
$ make_playoffs : int 0
$ make_superbowl : int 0
$ name : chr "MIN"
$ point_diff : int -45
$ points_allowed : int 475
$ points_scored : int 430
$ rating : num 1481
$ rating_current : num 1502
$ rating_top : num 1502
$ seed_1 : int 0
$ seed_2 : int 0
$ seed_3 : int 0
$ seed_4 : int 0
$ seed_5 : int 0
$ seed_6 : int 0
$ seed_7 : int 0
$ ties : int 0
$ win_division : int 0
$ win_superbowl : int 0
$ wins : int 7We can also play around with listviewer.
Since these are unique list elements, we can turn it into a dataframe! This is the current projection for Minnesota.
data.frame(ex_538_data) %>% glimpse()Rows: 1
Columns: 29
$ conference <chr> "NFC"
$ current_losses <int> 9
$ current_ties <int> 0
$ current_wins <int> 7
$ division <chr> "NFC North"
$ elo <dbl> 1489.284
$ losses <int> 9
$ make_conference_champ <int> 0
$ make_divisional_round <int> 0
$ make_playoffs <int> 0
$ make_superbowl <int> 0
$ name <chr> "MIN"
$ point_diff <int> -45
$ points_allowed <int> 475
$ points_scored <int> 430
$ rating <dbl> 1480.954
$ rating_current <dbl> 1501.583
$ rating_top <dbl> 1501.583
$ seed_1 <int> 0
$ seed_2 <int> 0
$ seed_3 <int> 0
$ seed_4 <int> 0
$ seed_5 <int> 0
$ seed_6 <int> 0
$ seed_7 <int> 0
$ ties <int> 0
$ win_division <int> 0
$ win_superbowl <int> 0
$ wins <int> 7Parse the JSON
Ok so we’ve found at least one set of data that is pretty dataframe ready, let’s clean it all up in bulk! I’m most interested in the weekly_forecasts data, so let’s start there.
List of 2
$ last_updated: chr "2021-02-08T03:15:55.357Z"
$ forecasts :List of 22Ok so last_updated is good to know, but not something I need right now. Let’s go one step deeper into forecasts.
List of 22
$ :List of 3
$ :List of 3
$ :List of 3
$ :List of 3
$ :List of 3
$ :List of 3
$ :List of 3
$ :List of 3
$ :List of 3
$ :List of 3
$ :List of 3
$ :List of 3
$ :List of 3
$ :List of 3
$ :List of 3
$ :List of 3
$ :List of 3
$ :List of 3
$ :List of 3
$ :List of 3
$ :List of 3
$ :List of 3Ok now we have a list of 14 lists. This may seem not helpful, BUT remember that as of 2020-12-12, we are in Week 14 of the NFL season! So this is likely 1 list for each of the weekly forecasts, which makes sense as we are in weekly_forecasts$forecasts!
At this point, I think I’m at the right data, so I’m going to take the list and put it in a tibble via tibble::enframe().
raw_538_json$weekly_forecasts$forecasts %>%
enframe()# A tibble: 22 × 2
name value
<int> <list>
1 1 <named list [3]>
2 2 <named list [3]>
3 3 <named list [3]>
4 4 <named list [3]>
5 5 <named list [3]>
6 6 <named list [3]>
7 7 <named list [3]>
8 8 <named list [3]>
9 9 <named list [3]>
10 10 <named list [3]>
# … with 12 more rowsWe need to separate the list items out, so we can try unnest_auto() to see if tidyr can parse the correct structure. Note that unnest_auto works and tells us we could have used unnest_wider().
Using `unnest_wider(value)`; elements have 3 names in common# A tibble: 22 × 4
name last_updated week types
<int> <chr> <int> <list>
1 1 2021-02-08T03:15:55.357Z 21 <named list [2]>
2 2 2021-01-25T03:10:04.809Z 20 <named list [2]>
3 3 2021-01-22T19:28:01.278Z 19 <named list [2]>
4 4 2021-01-15T01:25:55.192Z 18 <named list [2]>
5 5 2021-01-09T16:38:13.126Z 17 <named list [2]>
6 6 2021-01-03T16:03:42.517Z 16 <named list [2]>
7 7 2020-12-24T01:32:05.045Z 15 <named list [2]>
8 8 2020-12-16T14:13:49.344Z 14 <named list [2]>
9 9 2020-12-10T16:21:56.731Z 13 <named list [2]>
10 10 2020-12-06T15:29:51.523Z 12 <named list [2]>
# … with 12 more rowsWe can keep going on the types list column! Note that as unnest_auto() tells us “what” to do, I’m going to replace it with the appropriate function.
raw_538_json$weekly_forecasts$forecasts %>%
enframe() %>%
unnest_wider(value) %>% # changed per recommendation
unnest_auto(types)Using `unnest_wider(types)`; elements have 2 names in common# A tibble: 22 × 5
name last_updated week elo rating
<int> <chr> <int> <list> <list>
1 1 2021-02-08T03:15:55.357Z 21 <list [32]> <list [32]>
2 2 2021-01-25T03:10:04.809Z 20 <list [32]> <list [32]>
3 3 2021-01-22T19:28:01.278Z 19 <list [32]> <list [32]>
4 4 2021-01-15T01:25:55.192Z 18 <list [32]> <list [32]>
5 5 2021-01-09T16:38:13.126Z 17 <list [32]> <list [32]>
6 6 2021-01-03T16:03:42.517Z 16 <list [32]> <list [32]>
7 7 2020-12-24T01:32:05.045Z 15 <list [32]> <list [32]>
8 8 2020-12-16T14:13:49.344Z 14 <list [32]> <list [32]>
9 9 2020-12-10T16:21:56.731Z 13 <list [32]> <list [32]>
10 10 2020-12-06T15:29:51.523Z 12 <list [32]> <list [32]>
# … with 12 more rowsWe now have a list of 32 x 14 weeks. There are 32 teams so we’re most likely at the appropriate depth and can go longer vs wider now. We can also see that name/week don’t align so let’s drop name, and we can use unchop() to increase the length of the data for elo and rating at the same time.
raw_538_json$weekly_forecasts$forecasts %>%
enframe() %>%
unnest_wider(value) %>%
unnest_wider(types) %>% # Changed per recommendation
unchop(cols = c(elo, rating)) %>%
select(-name)# A tibble: 704 × 4
last_updated week elo rating
<chr> <int> <list> <list>
1 2021-02-08T03:15:55.357Z 21 <named list [29]> <named list [29]>
2 2021-02-08T03:15:55.357Z 21 <named list [29]> <named list [29]>
3 2021-02-08T03:15:55.357Z 21 <named list [29]> <named list [29]>
4 2021-02-08T03:15:55.357Z 21 <named list [29]> <named list [29]>
5 2021-02-08T03:15:55.357Z 21 <named list [29]> <named list [29]>
6 2021-02-08T03:15:55.357Z 21 <named list [29]> <named list [29]>
7 2021-02-08T03:15:55.357Z 21 <named list [29]> <named list [29]>
8 2021-02-08T03:15:55.357Z 21 <named list [29]> <named list [29]>
9 2021-02-08T03:15:55.357Z 21 <named list [29]> <named list [29]>
10 2021-02-08T03:15:55.357Z 21 <named list [29]> <named list [29]>
# … with 694 more rowsWe now have 14 weeks x 32 teams (448 rows), along with last_updated, week, elo and rating data. We can use unnest_auto() on the elo column to see what’s the next step. Rating is duplicated so there’s been name repair to avoid duplicated names. We get the following warning that tells us this has occurred.
* rating -> rating...18* rating -> rating...32
You’ll see that I’ve done unnest_auto() on both elo and rating...32 (the renamed rating list column). If you look closely at the names, we can also see that there is duplication of the names for MANY of the columns. A tricky part is that elo/rating each have a LOT of overlap, and are most appropriate as separate data frames that could be stacked if desired.
elo_raw <- raw_538_json$weekly_forecasts$forecasts %>%
enframe() %>%
unnest_wider(value) %>%
unnest_wider(types) %>% # Changed per recommendation
unchop(cols = c(elo, rating)) %>%
select(-name) %>%
unnest_auto(elo) %>%
unnest_auto(rating...32)Using `unnest_wider(elo)`; elements have 29 names in commonNew names:
Using `unnest_wider(rating...32)`; elements have 29 names in common
New names:
• `rating` -> `rating...18`
• `rating` -> `rating...32` [1] "last_updated" "week"
[3] "conference...3" "current_losses...4"
[5] "current_ties...5" "current_wins...6"
[7] "division...7" "elo...8"
[9] "losses...9" "make_conference_champ...10"
[11] "make_divisional_round...11" "make_playoffs...12"
[13] "make_superbowl...13" "name...14"
[15] "point_diff...15" "points_allowed...16"
[17] "points_scored...17" "rating...18"
[19] "rating_current...19" "rating_top...20"
[21] "seed_1...21" "seed_2...22"
[23] "seed_3...23" "seed_4...24"
[25] "seed_5...25" "seed_6...26"
[27] "seed_7...27" "ties...28"
[29] "win_division...29" "win_superbowl...30"
[31] "wins...31" "conference...32"
[33] "current_losses...33" "current_ties...34"
[35] "current_wins...35" "division...36"
[37] "elo...37" "losses...38"
[39] "make_conference_champ...39" "make_divisional_round...40"
[41] "make_playoffs...41" "make_superbowl...42"
[43] "name...43" "point_diff...44"
[45] "points_allowed...45" "points_scored...46"
[47] "rating...47" "rating_current...48"
[49] "rating_top...49" "seed_1...50"
[51] "seed_2...51" "seed_3...52"
[53] "seed_4...53" "seed_5...54"
[55] "seed_6...55" "seed_7...56"
[57] "ties...57" "win_division...58"
[59] "win_superbowl...59" "wins...60" Let’s try this again, with the knowledge that elo and rating should be treated separately for now. Since they have the same names, we can also combine the data by stacking (bind_rows()). I have added a new column so that we can differentiate between the two datasets (ELO vs Rating).
weekly_raw <- raw_538_json$weekly_forecasts$forecasts %>%
enframe() %>%
unnest_wider(value) %>%
unnest_wider(types) %>%
select(-name) %>%
unchop(cols = c(elo, rating))
weekly_elo <- weekly_raw %>%
select(-rating) %>%
unnest_wider(elo) %>%
mutate(measure = "ELO", .after = last_updated)
weekly_rating <- weekly_raw %>%
select(-elo) %>%
unnest_wider(rating) %>%
mutate(measure = "Rating", .after = last_updated)
# confirm same names
all.equal(
names(weekly_elo),
names(weekly_rating)
)[1] TRUEweekly_forecasts <- bind_rows(weekly_elo, weekly_rating)
weekly_forecasts %>% glimpse()Rows: 1,408
Columns: 32
$ last_updated <chr> "2021-02-08T03:15:55.357Z", "2021-02-08T03:15:55…
$ measure <chr> "ELO", "ELO", "ELO", "ELO", "ELO", "ELO", "ELO",…
$ week <int> 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, …
$ conference <chr> "NFC", "AFC", "NFC", "NFC", "NFC", "AFC", "AFC",…
$ current_losses <int> 9, 6, 10, 12, 11, 11, 14, 11, 6, 10, 6, 5, 10, 9…
$ current_ties <int> 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ current_wins <int> 7, 10, 7, 4, 5, 4, 2, 5, 12, 6, 11, 13, 6, 7, 15…
$ division <chr> "NFC North", "AFC East", "NFC East", "NFC South"…
$ elo <dbl> 1489.284, 1545.820, 1442.351, 1474.240, 1333.468…
$ losses <dbl> 9, 6, 9, 12, 11, 11, 14, 11, 5, 10, 5, 4, 10, 9,…
$ make_conference_champ <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, …
$ make_divisional_round <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1, 0, …
$ make_playoffs <dbl> 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 1, 1, 0, 0, 1, 1, …
$ make_superbowl <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ name <chr> "MIN", "MIA", "WSH", "ATL", "DET", "CIN", "NYJ",…
$ point_diff <dbl> -45, 66, 6, -18, -142, -113, -214, -123, 165, -7…
$ points_allowed <dbl> 475, 338, 329, 414, 519, 424, 457, 446, 303, 357…
$ points_scored <dbl> 430, 404, 335, 396, 377, 311, 243, 323, 468, 280…
$ rating <dbl> 1480.954, 1565.307, 1446.254, 1449.242, 1340.178…
$ rating_current <dbl> 1501.583, 1529.565, 1462.552, 1448.424, 1338.309…
$ rating_top <dbl> 1501.583, 1529.565, 1462.552, 1448.424, 1338.309…
$ seed_1 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ seed_2 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, …
$ seed_3 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, …
$ seed_4 <dbl> 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, …
$ seed_5 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, …
$ seed_6 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ seed_7 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ ties <dbl> 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ win_division <dbl> 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 1, 1, …
$ win_superbowl <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ wins <dbl> 7, 10, 7, 4, 5, 4, 2, 5, 11, 6, 11, 12, 6, 7, 13…Create a Function
Finally, we can combine the techniques we showed above as a function (and I’ve added it to espnscrapeR). Now we can use this to get data throughout the current season OR get info from past seasons (2015 and beyond). Again, note that 2015 has a different JSON structure but the core forecasts portion is still the same.
get_weekly_forecast <- function(season) {
# Fill URL and read in JSON
raw_url <- glue::glue("https://projects.fivethirtyeight.com/{season}-nfl-predictions/data.json")
raw_json <- fromJSON(raw_url, simplifyVector = FALSE)
# get the two datasets
weekly_raw <- raw_538_json$weekly_forecasts$forecasts %>%
enframe() %>%
unnest_wider(value) %>%
unnest_wider(types) %>%
select(-name) %>%
unchop(cols = c(elo, rating))
# get ELO
weekly_elo <- weekly_raw %>%
select(-rating) %>%
unnest_wider(elo) %>%
mutate(measure = "ELO", .after = last_updated)
# get Rating
weekly_rating <- weekly_raw %>%
select(-elo) %>%
unnest_wider(rating) %>%
mutate(measure = "Rating", .after = last_updated)
# combine
bind_rows(weekly_elo, weekly_rating)
}
get_weekly_forecast(2015) %>%
glimpse()Rows: 1,408
Columns: 32
$ last_updated <chr> "2021-02-08T03:15:55.357Z", "2021-02-08T03:15:55…
$ measure <chr> "ELO", "ELO", "ELO", "ELO", "ELO", "ELO", "ELO",…
$ week <int> 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, …
$ conference <chr> "NFC", "AFC", "NFC", "NFC", "NFC", "AFC", "AFC",…
$ current_losses <int> 9, 6, 10, 12, 11, 11, 14, 11, 6, 10, 6, 5, 10, 9…
$ current_ties <int> 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ current_wins <int> 7, 10, 7, 4, 5, 4, 2, 5, 12, 6, 11, 13, 6, 7, 15…
$ division <chr> "NFC North", "AFC East", "NFC East", "NFC South"…
$ elo <dbl> 1489.284, 1545.820, 1442.351, 1474.240, 1333.468…
$ losses <dbl> 9, 6, 9, 12, 11, 11, 14, 11, 5, 10, 5, 4, 10, 9,…
$ make_conference_champ <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, …
$ make_divisional_round <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1, 0, …
$ make_playoffs <dbl> 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 1, 1, 0, 0, 1, 1, …
$ make_superbowl <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ name <chr> "MIN", "MIA", "WSH", "ATL", "DET", "CIN", "NYJ",…
$ point_diff <dbl> -45, 66, 6, -18, -142, -113, -214, -123, 165, -7…
$ points_allowed <dbl> 475, 338, 329, 414, 519, 424, 457, 446, 303, 357…
$ points_scored <dbl> 430, 404, 335, 396, 377, 311, 243, 323, 468, 280…
$ rating <dbl> 1480.954, 1565.307, 1446.254, 1449.242, 1340.178…
$ rating_current <dbl> 1501.583, 1529.565, 1462.552, 1448.424, 1338.309…
$ rating_top <dbl> 1501.583, 1529.565, 1462.552, 1448.424, 1338.309…
$ seed_1 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ seed_2 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, …
$ seed_3 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, …
$ seed_4 <dbl> 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, …
$ seed_5 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, …
$ seed_6 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ seed_7 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ ties <dbl> 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ win_division <dbl> 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 1, 1, …
$ win_superbowl <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ wins <dbl> 7, 10, 7, 4, 5, 4, 2, 5, 11, 6, 11, 12, 6, 7, 13…Other FiveThirtyEight Data
There’s several other interesting data points in this JSON, but they’re also much easier to extract.
QB playoff adjustment values
Output
qb_playoff_adj# A tibble: 32 × 4
name team week qb_adj
<int> <chr> <int> <dbl>
1 1 ARI 21 17.3
2 2 ATL 21 -0.819
3 3 BAL 21 -2.72
4 4 BUF 21 33.1
5 5 CAR 21 4.26
6 6 CHI 21 19.2
7 7 CIN 21 -84.5
8 8 CLE 21 16.9
9 9 DAL 21 -60.9
10 10 DEN 21 15.3
# … with 22 more rowsGames Data
This one is interesting, it’s got ELO change as a result of win/loss along with the spread and ratings.
Using `unnest_wider(value)`; elements have 40 names in commonOutput
games_df# A tibble: 269 × 40
id date datetime week status team1 team2 neutral playoff score1 score2
<int> <chr> <chr> <int> <chr> <chr> <chr> <lgl> <chr> <int> <int>
1 4.01e8 2020… 2020-09… 1 post KC HOU FALSE <NA> 34 20
2 4.01e8 2020… 2020-09… 1 post DET CHI FALSE <NA> 23 27
3 4.01e8 2020… 2020-09… 1 post BAL CLE FALSE <NA> 38 6
4 4.01e8 2020… 2020-09… 1 post MIN GB FALSE <NA> 34 43
5 4.01e8 2020… 2020-09… 1 post JAX IND FALSE <NA> 27 20
6 4.01e8 2020… 2020-09… 1 post NE MIA FALSE <NA> 21 11
7 4.01e8 2020… 2020-09… 1 post BUF NYJ FALSE <NA> 27 17
8 4.01e8 2020… 2020-09… 1 post CAR OAK FALSE <NA> 30 34
9 4.01e8 2020… 2020-09… 1 post WSH PHI FALSE <NA> 27 17
10 4.01e8 2020… 2020-09… 1 post ATL SEA FALSE <NA> 25 38
# … with 259 more rows, and 29 more variables: overtime <lgl>, elo1_pre <dbl>,
# elo2_pre <dbl>, elo_spread <dbl>, elo_prob1 <dbl>, elo_prob2 <dbl>,
# elo1_post <dbl>, elo2_post <dbl>, rating1_pre <dbl>, rating2_pre <dbl>,
# rating_spread <dbl>, rating_prob1 <dbl>, rating_prob2 <dbl>,
# rating1_post <dbl>, rating2_post <dbl>, bettable <lgl>, outcome <dbl>,
# qb_adj1 <dbl>, qb_adj2 <dbl>, rest_adj1 <int>, rest_adj2 <int>,
# dist_adj <dbl>, rating1_top_qb <dbl>, rating2_top_qb <dbl>, …Distances
This data has the distances for each team to other locations/stadiums.
Output
distance_df# A tibble: 1,024 × 6
name team lat lon distances distances_id
<int> <chr> <dbl> <dbl> <dbl> <chr>
1 1 TEN 36.2 -86.8 0 TEN
2 1 TEN 36.2 -86.8 758. NYG
3 1 TEN 36.2 -86.8 471. PIT
4 1 TEN 36.2 -86.8 339. CAR
5 1 TEN 36.2 -86.8 595. BAL
6 1 TEN 36.2 -86.8 619. TB
7 1 TEN 36.2 -86.8 251. IND
8 1 TEN 36.2 -86.8 698. MIN
9 1 TEN 36.2 -86.8 1454. ARI
10 1 TEN 36.2 -86.8 634. DAL
# … with 1,014 more rowsQB Adjustment
I believe this is the in-season QB adjustment for each team.
Output
qb_adj# A tibble: 87 × 6
api_id name team priority elo_value starts
<int> <chr> <chr> <int> <int> <int>
1 3040206 Chris Streveler ARI 2 0 1
2 4035003 Jacob Eason IND 3 58 1
3 3124900 Jake Luton JAX 3 20 1
4 3915436 Steven Montez WSH 3 0 1
5 4241479 Tua Tagovailoa MIA 1 128 1
6 4038941 Justin Herbert LAC 1 200 1
7 4040715 Jalen Hurts PHI 1 120 1
8 3895785 Ben DiNucci DAL 3 6 1
9 4036378 Jordan Love GB 3 102 1
10 12471 Chase Daniel DET 2 33 1
# … with 77 more rowsESPN
ESPN has interactive win probability charts for their games. They also go a step farther than FiveThirtyEight and the JSON is embedded into the HTML “bundle”. They also have a hidden API, but I’m going to first show an example of how to get the JSON from within the page itself.
Example End Function
get_espn_win_prob <- function(game_id){
raw_url <-glue::glue("https://www.espn.com/nfl/game?gameId={game_id}")
raw_html <- raw_url %>%
read_html()
raw_text <- raw_html %>%
html_nodes("script") %>%
.[23] %>%
html_text()
raw_json <- raw_text %>%
gsub(".*(\\[\\{)", "\\1", .) %>%
gsub("(\\}\\]).*", "\\1", .)
parsed_json <- jsonlite::parse_json(raw_json)
raw_df <- parsed_json %>%
enframe() %>%
rename(row_id = name) %>%
unnest_wider(value) %>%
unnest_wider(play) %>%
hoist(period, quarter = "number") %>%
unnest_wider(start) %>%
hoist(team, pos_team_id = "id") %>%
hoist(clock, clock = "displayValue") %>%
hoist(type, play_type = "text") %>%
select(-type) %>%
janitor::clean_names() %>%
mutate(game_id = game_id)
raw_df
}Get the data
Let’s use an example from a pretty wild swing in Win Percentage from Week 13 of the 2020 NFL season. The Vikings and Jaguars went to overtime, with a lot of back and forth. Since there is an interactive data visualization, I’m assuming the JSON data is present there as well.
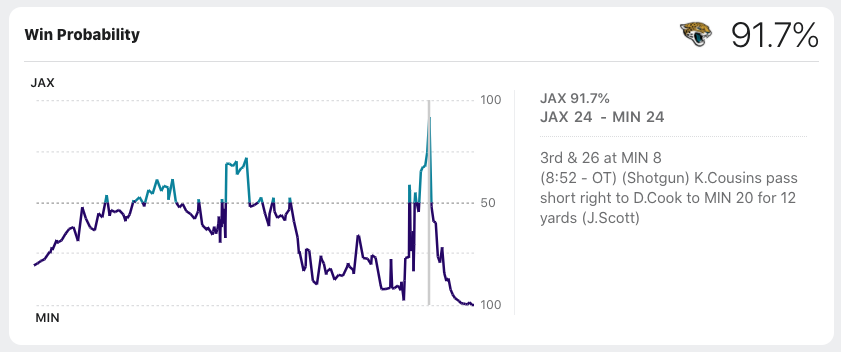
If we try our previous trick from FiveThirtyEight and the Inspect -> Network we get a total of… about 300 different requests! None of them appear big enough to be the “right” data. We’re expecting 4-5 Mb of data.
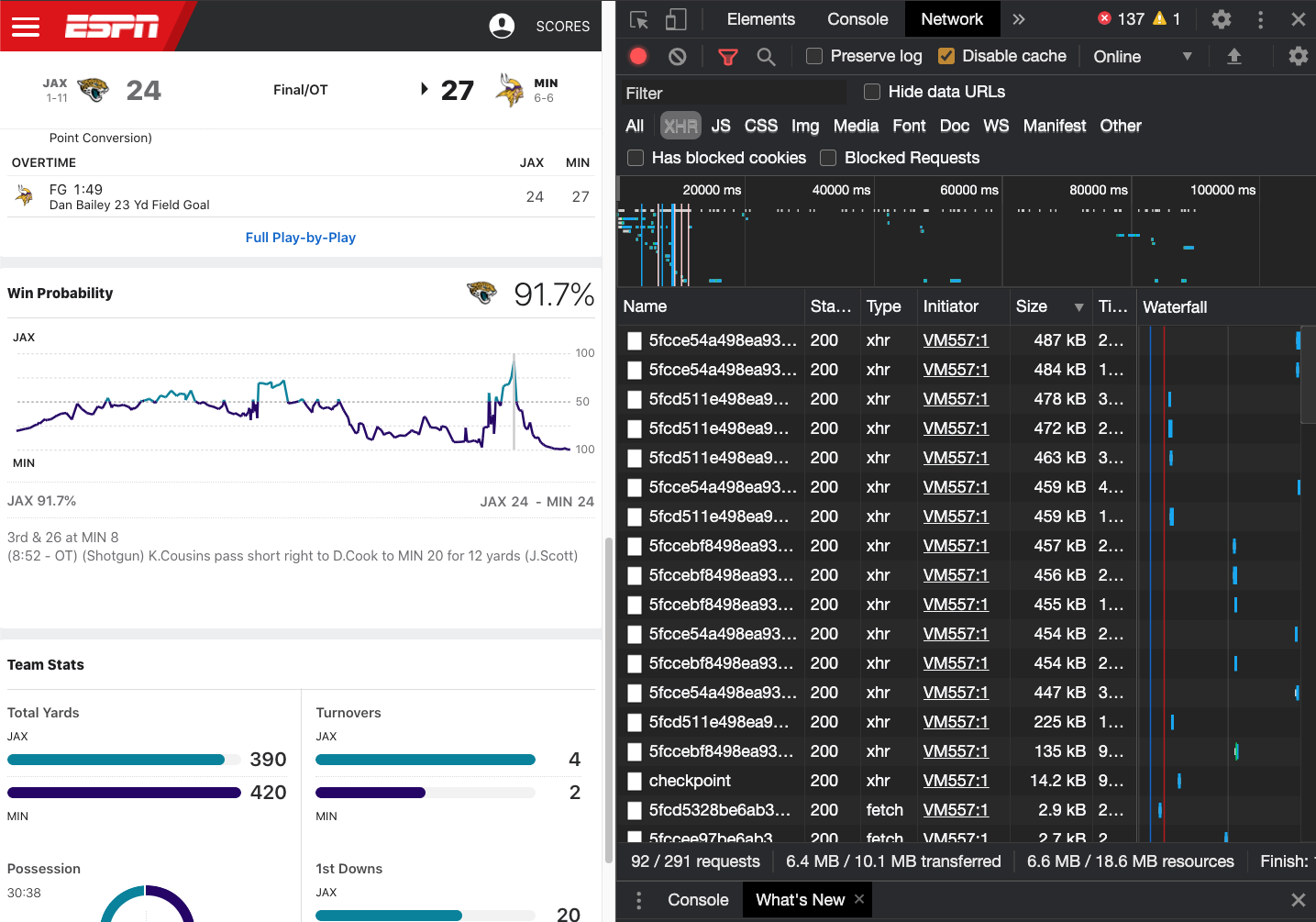
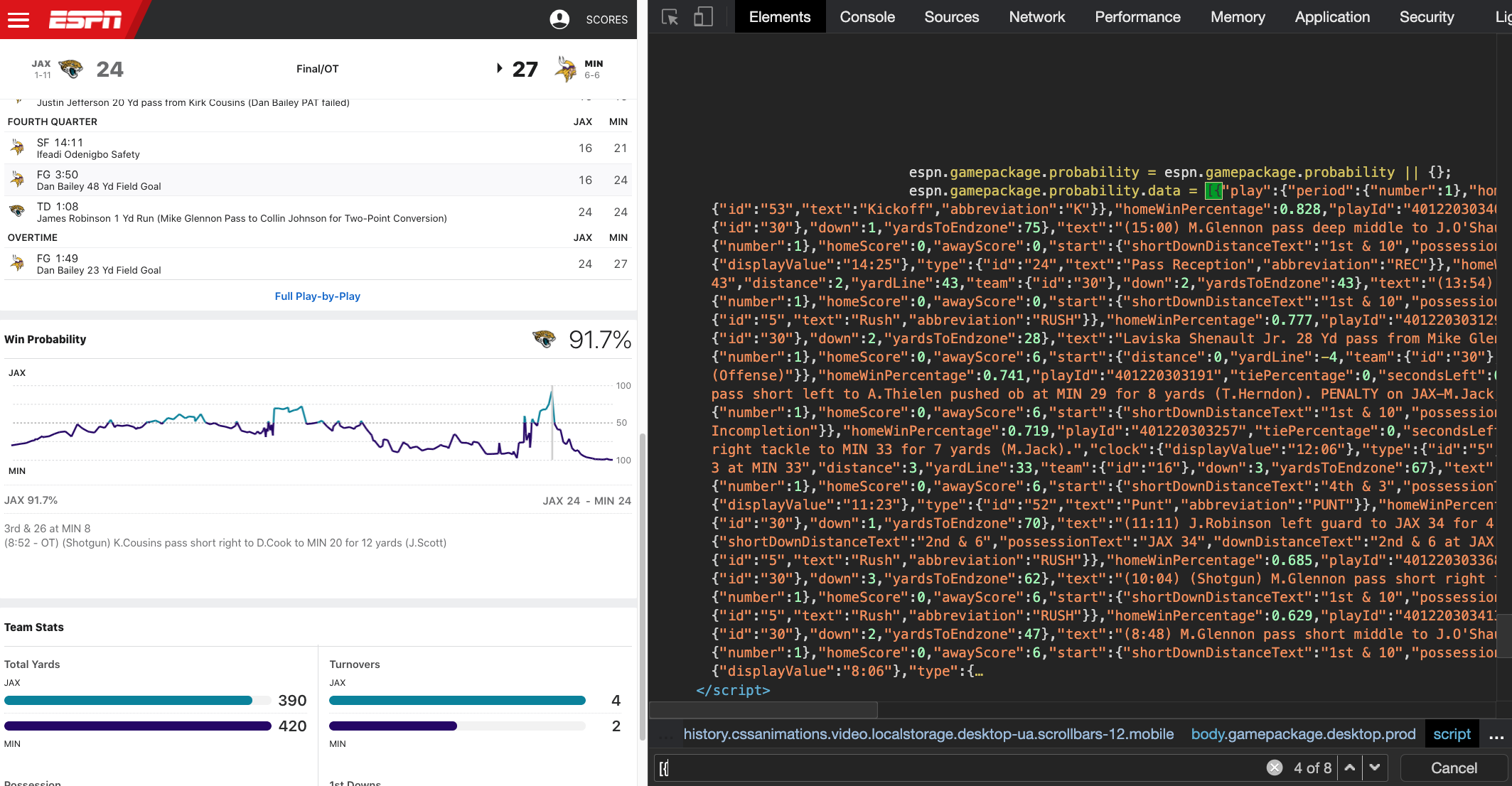
Another trick is to look for embedded JSON in the site itself. The basic representation of JSON is [{name: item}], so let’s try looking for [{ as the start of a JSON structure.
Inside the Google Chrome Dev tools we can search and find a few JSON files, including one inside some JavaScript called espn.gamepackage.probability! There’s a good amount of data there, but we need to extract it from the raw HTML. This JSON is inside a <script> object, so let’s parse the HTML and get script nodes.
espn_url <-glue::glue("https://www.espn.com/nfl/game?gameId=401220303")
raw_espn_html <- espn_url %>%
read_html()
raw_espn_html %>%
html_nodes("script") {xml_nodeset (27)}
[1] <script type="application/ld+json">\n\t{\n\t\t"@context": "https://schem ...
[2] <script type="text/javascript" src="https://dcf.espn.com/TWDC-DTCI/prod/ ...
[3] <script type="text/javascript">\n;(function(){\n\nfunction rc(a){for(var ...
[4] <script src="https://secure.espn.com/core/format/modules/head/i18n?editi ...
[5] <script src="https://a.espncdn.com/redesign/0.591.3/js/espn-head.js"></s ...
[6] <script>\n\t\t\tif (espn && espn.geoRedirect){\n\t\t\t\tespn.geoRedirect ...
[7] <script>\n\tvar espn = espn || {};\n\tespn.isOneSite = false;\n\tespn.bu ...
[8] <script src="https://a.espncdn.com/redesign/0.591.3/node_modules/espn-la ...
[9] <script type="text/javascript">\n\t(function () {\n\t\tvar featureGating ...
[10] <script>\n\t\twindow.googletag = window.googletag || {};\n\n\t\t(functio ...
[11] <script type="text/javascript">\n\tif( typeof s_omni === "undefined" ) w ...
[12] <script type="text/javascript" src="https://a.espncdn.com/prod/scripts/a ...
[13] <script>\n\t// Picture element HTML shim|v it for old IE (pairs with Pic ...
[14] <script type="text/javascript">\n\t\t\tvar abtestData = {};\n\t\t\t\n\t\ ...
[15] <script type="text/javascript">\n\t\tvar espn = espn || {};\n\t\tespn.na ...
[16] <script type="text/javascript">\n\n var __dataLayer = window.__dataLa ...
[17] <script>\n\tvar espn_ui = window.espn_ui || {};\n\tespn_ui.staticRef = " ...
[18] <script src="https://a.espncdn.com/redesign/0.591.3/js/espn-critical.js" ...
[19] <script type="text/javascript">\n\t\t\tvar espn = espn || {};\n\n\t\t\t/ ...
[20] <script type="text/javascript">jQuery.subscribe('espn.defer.end', functi ...
...Big oof. There’s 27 scripts here and just parsing through the start of the script as they are in XML is not helpful…So let’s get the raw text from each of these nodes and see if we can find the espn.gamepackage.probability element which we’re looking for!
raw_espn_text <- raw_espn_html %>%
html_nodes("script") %>%
html_text()
raw_espn_text %>%
str_which("espn.gamepackage.probability")[1] 23Ok! So we’re looking for the 23rd node, I’m going to hide the output inside an expandable tag, as it’s a long output!
example_embed_json <- raw_espn_html %>%
html_nodes("script") %>%
.[23] %>%
html_text()Example Embed JSON
example_embed_json[1] "\n\t\t\t\t(function($) {\n\t\t\t\t\tvar espn = window.espn || {},\n\t\t\t\t\t\tDTCpackages = window.DTCpackages || [];\n\n\t\t\t\t\tespn.gamepackage = espn.gamepackage || {};\n\t\t\t\t\tespn.gamepackage.gameId = \"401220303\";\n\t\t\t\t\tespn.gamepackage.type = \"game\";\n\t\t\t\t\tespn.gamepackage.timestamp = \"2020-12-06T18:00Z\";\n\t\t\t\t\tespn.gamepackage.status = \"post\";\n\t\t\t\t\tespn.gamepackage.league = \"nfl\";\n\t\t\t\t\tespn.gamepackage.leagueId = 28;\n\t\t\t\t\tespn.gamepackage.sport = \"football\";\n\t\t\t\t\tespn.gamepackage.network = \"CBS\";\n\t\t\t\t\tespn.gamepackage.awayTeamName = \"jacksonville-jaguars\";\n\t\t\t\t\tespn.gamepackage.homeTeamName = \"minnesota-vikings\";\n\t\t\t\t\tespn.gamepackage.awayTeamId = \"30\";\n\t\t\t\t\tespn.gamepackage.homeTeamId = \"16\";\n\t\t\t\t\tespn.gamepackage.awayTeamColor = \"00839C\";\n\t\t\t\t\tespn.gamepackage.homeTeamColor = \"240A67\";\n\t\t\t\t\tespn.gamepackage.showGamebreak = true;\n\t\t\t\t\tespn.gamepackage.supportsHeadshots = true\n\t\t\t\t\tespn.gamepackage.playByPlaySource = \"full\";\n\t\t\t\t\tespn.gamepackage.numPeriods = null;\n\t\t\t\t\t\n\t\t\t\t\t\n\t\t\t\t\t\n\t\t\t\t\t\n\n\t\t\t\t\t\n\n\t\t\t\t\t\n\t\t\t\t\t\tespn.gamepackage.probability = espn.gamepackage.probability || {};\n\t\t\t\t\t\tespn.gamepackage.probability.data = [{\"play\":{\"period\":{\"number\":1},\"homeScore\":0,\"awayScore\":0,\"start\":{\"distance\":0,\"yardLine\":35,\"team\":{\"id\":\"16\"},\"down\":0,\"yardsToEndzone\":65},\"text\":\"D.Bailey kicks 65 yards from MIN 35 to end zone, Touchback.\",\"clock\":{\"displayValue\":\"15:00\"},\"type\":{\"id\":\"53\",\"text\":\"Kickoff\",\"abbreviation\":\"K\"}},\"homeWinPercentage\":0.828,\"playId\":\"40122030340\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":1},\"homeScore\":0,\"awayScore\":0,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"JAX 25\",\"downDistanceText\":\"1st & 10 at JAX 25\",\"distance\":10,\"yardLine\":75,\"team\":{\"id\":\"30\"},\"down\":1,\"yardsToEndzone\":75},\"text\":\"(15:00) M.Glennon pass deep middle to J.O'Shaughnessy to JAX 49 for 24 yards (A.Harris; E.Wilson).\",\"clock\":{\"displayValue\":\"15:00\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.807,\"playId\":\"40122030355\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":1},\"homeScore\":0,\"awayScore\":0,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"JAX 49\",\"downDistanceText\":\"1st & 10 at JAX 49\",\"distance\":10,\"yardLine\":51,\"team\":{\"id\":\"30\"},\"down\":1,\"yardsToEndzone\":51},\"text\":\"(14:25) (Shotgun) M.Glennon pass short right to J.Robinson pushed ob at MIN 43 for 8 yards (T.Dye).\",\"clock\":{\"displayValue\":\"14:25\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.796,\"playId\":\"40122030379\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":1},\"homeScore\":0,\"awayScore\":0,\"start\":{\"shortDownDistanceText\":\"2nd & 2\",\"possessionText\":\"MIN 43\",\"downDistanceText\":\"2nd & 2 at MIN 43\",\"distance\":2,\"yardLine\":43,\"team\":{\"id\":\"30\"},\"down\":2,\"yardsToEndzone\":43},\"text\":\"(13:54) J.Robinson left guard to MIN 34 for 9 yards (T.Davis; E.Wilson).\",\"clock\":{\"displayValue\":\"13:54\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.785,\"playId\":\"401220303108\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":1},\"homeScore\":0,\"awayScore\":0,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"MIN 34\",\"downDistanceText\":\"1st & 10 at MIN 34\",\"distance\":10,\"yardLine\":34,\"team\":{\"id\":\"30\"},\"down\":1,\"yardsToEndzone\":34},\"text\":\"(13:21) J.Robinson left end to MIN 28 for 6 yards (A.Harris; S.Stephen).\",\"clock\":{\"displayValue\":\"13:21\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.777,\"playId\":\"401220303129\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":1},\"homeScore\":0,\"awayScore\":6,\"start\":{\"shortDownDistanceText\":\"2nd & 4\",\"possessionText\":\"MIN 28\",\"downDistanceText\":\"2nd & 4 at MIN 28\",\"distance\":4,\"yardLine\":28,\"team\":{\"id\":\"30\"},\"down\":2,\"yardsToEndzone\":28},\"text\":\"Laviska Shenault Jr. 28 Yd pass from Mike Glennon (Chase McLaughlin PAT failed)\",\"clock\":{\"displayValue\":\"12:33\"},\"type\":{\"id\":\"67\",\"text\":\"Passing Touchdown\",\"abbreviation\":\"TD\"}},\"homeWinPercentage\":0.742,\"playId\":\"401220303150\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":1},\"homeScore\":0,\"awayScore\":6,\"start\":{\"distance\":0,\"yardLine\":-4,\"team\":{\"id\":\"30\"},\"down\":0,\"yardsToEndzone\":65},\"text\":\"L.Cooke kicks 69 yards from JAX 35 to MIN -4. A.Abdullah to MIN 21 for 25 yards (S.Quarterman).\",\"clock\":{\"displayValue\":\"12:33\"},\"type\":{\"id\":\"12\",\"text\":\"Kickoff Return (Offense)\"}},\"homeWinPercentage\":0.741,\"playId\":\"401220303191\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":1},\"homeScore\":0,\"awayScore\":6,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"MIN 21\",\"downDistanceText\":\"1st & 10 at MIN 21\",\"distance\":10,\"yardLine\":21,\"team\":{\"id\":\"16\"},\"down\":1,\"yardsToEndzone\":79},\"text\":\"(12:28) K.Cousins pass short left to A.Thielen pushed ob at MIN 29 for 8 yards (T.Herndon). PENALTY on JAX-M.Jack, Defensive Holding, 5 yards, enforced at MIN 21 - No Play.\",\"clock\":{\"displayValue\":\"12:28\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.747,\"playId\":\"401220303213\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":1},\"homeScore\":0,\"awayScore\":6,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"MIN 26\",\"downDistanceText\":\"1st & 10 at MIN 26\",\"distance\":10,\"yardLine\":26,\"team\":{\"id\":\"16\"},\"down\":1,\"yardsToEndzone\":74},\"text\":\"(12:11) (Shotgun) K.Cousins pass incomplete deep right to A.Thielen.\",\"clock\":{\"displayValue\":\"12:11\"},\"type\":{\"id\":\"3\",\"text\":\"Pass Incompletion\"}},\"homeWinPercentage\":0.719,\"playId\":\"401220303257\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":1},\"homeScore\":0,\"awayScore\":6,\"start\":{\"shortDownDistanceText\":\"2nd & 10\",\"possessionText\":\"MIN 26\",\"downDistanceText\":\"2nd & 10 at MIN 26\",\"distance\":10,\"yardLine\":26,\"team\":{\"id\":\"16\"},\"down\":2,\"yardsToEndzone\":74},\"text\":\"(12:06) D.Cook right tackle to MIN 33 for 7 yards (M.Jack).\",\"clock\":{\"displayValue\":\"12:06\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.731,\"playId\":\"401220303279\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":1},\"homeScore\":0,\"awayScore\":6,\"start\":{\"shortDownDistanceText\":\"3rd & 3\",\"possessionText\":\"MIN 33\",\"downDistanceText\":\"3rd & 3 at MIN 33\",\"distance\":3,\"yardLine\":33,\"team\":{\"id\":\"16\"},\"down\":3,\"yardsToEndzone\":67},\"text\":\"(11:27) (Shotgun) K.Cousins pass incomplete short right to D.Cook.\",\"clock\":{\"displayValue\":\"11:27\"},\"type\":{\"id\":\"3\",\"text\":\"Pass Incompletion\"}},\"homeWinPercentage\":0.683,\"playId\":\"401220303300\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":1},\"homeScore\":0,\"awayScore\":6,\"start\":{\"shortDownDistanceText\":\"4th & 3\",\"possessionText\":\"MIN 33\",\"downDistanceText\":\"4th & 3 at MIN 33\",\"distance\":3,\"yardLine\":33,\"team\":{\"id\":\"16\"},\"down\":4,\"yardsToEndzone\":67},\"text\":\"(11:23) B.Colquitt punts 50 yards to JAX 17, Center-A.DePaola. K.Cole Sr. to JAX 30 for 13 yards (T.Conklin).\",\"clock\":{\"displayValue\":\"11:23\"},\"type\":{\"id\":\"52\",\"text\":\"Punt\",\"abbreviation\":\"PUNT\"}},\"homeWinPercentage\":0.699,\"playId\":\"401220303322\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":1},\"homeScore\":0,\"awayScore\":6,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"JAX 30\",\"downDistanceText\":\"1st & 10 at JAX 30\",\"distance\":10,\"yardLine\":70,\"team\":{\"id\":\"30\"},\"down\":1,\"yardsToEndzone\":70},\"text\":\"(11:11) J.Robinson left guard to JAX 34 for 4 yards (T.Dye).\",\"clock\":{\"displayValue\":\"11:11\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.693,\"playId\":\"401220303347\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":1},\"homeScore\":0,\"awayScore\":6,\"start\":{\"shortDownDistanceText\":\"2nd & 6\",\"possessionText\":\"JAX 34\",\"downDistanceText\":\"2nd & 6 at JAX 34\",\"distance\":6,\"yardLine\":66,\"team\":{\"id\":\"30\"},\"down\":2,\"yardsToEndzone\":66},\"text\":\"(10:41) (Shotgun) J.Robinson left end to JAX 38 for 4 yards (T.Davis; J.Johnson).\",\"clock\":{\"displayValue\":\"10:41\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.685,\"playId\":\"401220303368\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":1},\"homeScore\":0,\"awayScore\":6,\"start\":{\"shortDownDistanceText\":\"3rd & 2\",\"possessionText\":\"JAX 38\",\"downDistanceText\":\"3rd & 2 at JAX 38\",\"distance\":2,\"yardLine\":62,\"team\":{\"id\":\"30\"},\"down\":3,\"yardsToEndzone\":62},\"text\":\"(10:04) (Shotgun) M.Glennon pass short right to T.Eifert to JAX 44 for 6 yards (J.Gladney).\",\"clock\":{\"displayValue\":\"10:04\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.653,\"playId\":\"401220303389\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":1},\"homeScore\":0,\"awayScore\":6,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"JAX 44\",\"downDistanceText\":\"1st & 10 at JAX 44\",\"distance\":10,\"yardLine\":56,\"team\":{\"id\":\"30\"},\"down\":1,\"yardsToEndzone\":56},\"text\":\"(9:29) J.Robinson left tackle to MIN 47 for 9 yards (E.Wilson).\",\"clock\":{\"displayValue\":\"9:29\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.629,\"playId\":\"401220303413\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":1},\"homeScore\":0,\"awayScore\":6,\"start\":{\"shortDownDistanceText\":\"2nd & 1\",\"possessionText\":\"MIN 47\",\"downDistanceText\":\"2nd & 1 at MIN 47\",\"distance\":1,\"yardLine\":47,\"team\":{\"id\":\"30\"},\"down\":2,\"yardsToEndzone\":47},\"text\":\"(8:48) M.Glennon pass short middle to J.O'Shaughnessy to MIN 40 for 7 yards (T.Dye).\",\"clock\":{\"displayValue\":\"8:48\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.62,\"playId\":\"401220303434\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":1},\"homeScore\":0,\"awayScore\":6,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"MIN 40\",\"downDistanceText\":\"1st & 10 at MIN 40\",\"distance\":10,\"yardLine\":40,\"team\":{\"id\":\"30\"},\"down\":1,\"yardsToEndzone\":40},\"text\":\"(8:06) (Shotgun) M.Glennon pass deep left to C.Johnson to MIN 6 for 34 yards (H.Smith) [J.Holmes].\",\"clock\":{\"displayValue\":\"8:06\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.688,\"playId\":\"401220303458\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":1},\"homeScore\":0,\"awayScore\":6,\"start\":{\"shortDownDistanceText\":\"1st & Goal\",\"possessionText\":\"MIN 6\",\"downDistanceText\":\"1st & Goal at MIN 6\",\"distance\":6,\"yardLine\":6,\"team\":{\"id\":\"30\"},\"down\":1,\"yardsToEndzone\":6},\"text\":\"(7:28) (Shotgun) M.Glennon pass short right to J.Robinson to MIN 5 for 1 yard (T.Dye).\",\"clock\":{\"displayValue\":\"7:26\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.523,\"playId\":\"401220303482\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":1},\"homeScore\":0,\"awayScore\":6,\"start\":{\"shortDownDistanceText\":\"2nd & Goal\",\"possessionText\":\"MIN 5\",\"downDistanceText\":\"2nd & Goal at MIN 5\",\"distance\":5,\"yardLine\":5,\"team\":{\"id\":\"30\"},\"down\":2,\"yardsToEndzone\":5},\"text\":\"(6:52) (Shotgun) J.Robinson up the middle to MIN 4 for 1 yard (E.Yarbrough; J.Gladney).\",\"clock\":{\"displayValue\":\"6:52\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.578,\"playId\":\"401220303506\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":1},\"homeScore\":0,\"awayScore\":6,\"start\":{\"shortDownDistanceText\":\"3rd & Goal\",\"possessionText\":\"MIN 4\",\"downDistanceText\":\"3rd & Goal at MIN 4\",\"distance\":4,\"yardLine\":4,\"team\":{\"id\":\"30\"},\"down\":3,\"yardsToEndzone\":4},\"text\":\"(6:12) (Shotgun) M.Glennon pass incomplete short left to K.Cole Sr..\",\"clock\":{\"displayValue\":\"6:12\"},\"type\":{\"id\":\"3\",\"text\":\"Pass Incompletion\"}},\"homeWinPercentage\":0.621,\"playId\":\"401220303527\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":1},\"homeScore\":0,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"4th & Goal\",\"possessionText\":\"MIN 4\",\"downDistanceText\":\"4th & Goal at MIN 4\",\"distance\":4,\"yardLine\":4,\"team\":{\"id\":\"30\"},\"down\":4,\"yardsToEndzone\":4},\"text\":\"Chase McLaughlin 22 Yd Field Goal\",\"clock\":{\"displayValue\":\"6:04\"},\"type\":{\"id\":\"59\",\"text\":\"Field Goal Good\",\"abbreviation\":\"FG\"}},\"homeWinPercentage\":0.619,\"playId\":\"401220303549\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":1},\"homeScore\":0,\"awayScore\":9,\"start\":{\"distance\":0,\"yardLine\":65,\"team\":{\"id\":\"30\"},\"down\":0,\"yardsToEndzone\":65},\"text\":\"L.Cooke kicks 65 yards from JAX 35 to end zone, Touchback.\",\"clock\":{\"displayValue\":\"6:04\"},\"type\":{\"id\":\"53\",\"text\":\"Kickoff\",\"abbreviation\":\"K\"}},\"homeWinPercentage\":0.624,\"playId\":\"401220303568\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":1},\"homeScore\":0,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"MIN 25\",\"downDistanceText\":\"1st & 10 at MIN 25\",\"distance\":10,\"yardLine\":25,\"team\":{\"id\":\"16\"},\"down\":1,\"yardsToEndzone\":75},\"text\":\"(6:04) D.Cook left end to MIN 31 for 6 yards (J.Schobert).\",\"clock\":{\"displayValue\":\"6:04\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.625,\"playId\":\"401220303583\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":1},\"homeScore\":0,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"2nd & 4\",\"possessionText\":\"MIN 31\",\"downDistanceText\":\"2nd & 4 at MIN 31\",\"distance\":4,\"yardLine\":31,\"team\":{\"id\":\"16\"},\"down\":2,\"yardsToEndzone\":69},\"text\":\"(5:28) K.Cousins pass short left to J.Jefferson to MIN 36 for 5 yards (T.Herndon).\",\"clock\":{\"displayValue\":\"5:28\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.636,\"playId\":\"401220303604\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":1},\"homeScore\":0,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"MIN 36\",\"downDistanceText\":\"1st & 10 at MIN 36\",\"distance\":10,\"yardLine\":36,\"team\":{\"id\":\"16\"},\"down\":1,\"yardsToEndzone\":64},\"text\":\"(4:53) J.Jefferson right end pushed ob at MIN 38 for 2 yards (M.Jack).\",\"clock\":{\"displayValue\":\"4:53\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.553,\"playId\":\"401220303628\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":1},\"homeScore\":0,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"2nd & 8\",\"possessionText\":\"MIN 38\",\"downDistanceText\":\"2nd & 8 at MIN 38\",\"distance\":8,\"yardLine\":38,\"team\":{\"id\":\"16\"},\"down\":2,\"yardsToEndzone\":62},\"text\":\"(4:17) D.Cook left end to MIN 35 for -3 yards (T.Herndon).\",\"clock\":{\"displayValue\":\"4:17\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.572,\"playId\":\"401220303649\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":1},\"homeScore\":0,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"3rd & 11\",\"possessionText\":\"MIN 35\",\"downDistanceText\":\"3rd & 11 at MIN 35\",\"distance\":11,\"yardLine\":35,\"team\":{\"id\":\"16\"},\"down\":3,\"yardsToEndzone\":65},\"text\":\"(3:36) (Shotgun) K.Cousins sacked at MIN 30 for -5 yards (D.Smoot).\",\"clock\":{\"displayValue\":\"3:36\"},\"type\":{\"id\":\"7\",\"text\":\"Sack\"}},\"homeWinPercentage\":0.464,\"playId\":\"401220303670\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":1},\"homeScore\":0,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"4th & 16\",\"possessionText\":\"MIN 30\",\"downDistanceText\":\"4th & 16 at MIN 30\",\"distance\":16,\"yardLine\":30,\"team\":{\"id\":\"16\"},\"down\":4,\"yardsToEndzone\":70},\"text\":\"(3:08) B.Colquitt punts 49 yards to JAX 21, Center-A.DePaola. K.Cole Sr. to JAX 25 for 4 yards (R.Connelly). PENALTY on JAX-J.Giles-Harris, Offensive Holding, 10 yards, enforced at JAX 21.\",\"clock\":{\"displayValue\":\"3:08\"},\"type\":{\"id\":\"52\",\"text\":\"Punt\",\"abbreviation\":\"PUNT\"}},\"homeWinPercentage\":0.565,\"playId\":\"401220303689\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":1},\"homeScore\":0,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"JAX 11\",\"downDistanceText\":\"1st & 10 at JAX 11\",\"distance\":10,\"yardLine\":89,\"team\":{\"id\":\"30\"},\"down\":1,\"yardsToEndzone\":89},\"text\":\"(2:56) L.Shenault Jr. left end to JAX 24 for 13 yards (T.Davis).\",\"clock\":{\"displayValue\":\"2:56\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.537,\"playId\":\"401220303731\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":1},\"homeScore\":0,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"JAX 24\",\"downDistanceText\":\"1st & 10 at JAX 24\",\"distance\":10,\"yardLine\":76,\"team\":{\"id\":\"30\"},\"down\":1,\"yardsToEndzone\":76},\"text\":\"(2:17) J.Robinson up the middle to JAX 28 for 4 yards (H.Mata'afa; T.Davis).\",\"clock\":{\"displayValue\":\"2:17\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.547,\"playId\":\"401220303752\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":1},\"homeScore\":0,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"2nd & 6\",\"possessionText\":\"JAX 28\",\"downDistanceText\":\"2nd & 6 at JAX 28\",\"distance\":6,\"yardLine\":72,\"team\":{\"id\":\"30\"},\"down\":2,\"yardsToEndzone\":72},\"text\":\"(1:41) M.Glennon pass short right to J.O'Shaughnessy to JAX 32 for 4 yards (J.Gladney).\",\"clock\":{\"displayValue\":\"1:41\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.536,\"playId\":\"401220303773\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":1},\"homeScore\":0,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"3rd & 2\",\"possessionText\":\"JAX 32\",\"downDistanceText\":\"3rd & 2 at JAX 32\",\"distance\":2,\"yardLine\":68,\"team\":{\"id\":\"30\"},\"down\":3,\"yardsToEndzone\":68},\"text\":\"(:59) (Shotgun) PENALTY on JAX-J.Robinson, False Start, 5 yards, enforced at JAX 32 - No Play.\",\"clock\":{\"displayValue\":\"0:59\"},\"type\":{\"id\":\"8\",\"text\":\"Penalty\",\"abbreviation\":\"PEN\"}},\"homeWinPercentage\":0.559,\"playId\":\"401220303797\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":1},\"homeScore\":0,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"3rd & 7\",\"possessionText\":\"JAX 27\",\"downDistanceText\":\"3rd & 7 at JAX 27\",\"distance\":7,\"yardLine\":73,\"team\":{\"id\":\"30\"},\"down\":3,\"yardsToEndzone\":73},\"text\":\"(:38) (Shotgun) M.Glennon pass incomplete short right to D.Chark Jr..\",\"clock\":{\"displayValue\":\"0:38\"},\"type\":{\"id\":\"3\",\"text\":\"Pass Incompletion\"}},\"homeWinPercentage\":0.591,\"playId\":\"401220303820\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":1},\"homeScore\":0,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"4th & 7\",\"possessionText\":\"JAX 27\",\"downDistanceText\":\"4th & 7 at JAX 27\",\"distance\":7,\"yardLine\":73,\"team\":{\"id\":\"30\"},\"down\":4,\"yardsToEndzone\":73},\"text\":\"(:33) L.Cooke punts 59 yards to MIN 14, Center-R.Matiscik. K.Osborn to MIN 21 for 7 yards (D.Ogunbowale).\",\"clock\":{\"displayValue\":\"0:33\"},\"type\":{\"id\":\"52\",\"text\":\"Punt\",\"abbreviation\":\"PUNT\"}},\"homeWinPercentage\":0.567,\"playId\":\"401220303842\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":1},\"homeScore\":0,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"MIN 21\",\"downDistanceText\":\"1st & 10 at MIN 21\",\"distance\":10,\"yardLine\":21,\"team\":{\"id\":\"16\"},\"down\":1,\"yardsToEndzone\":79},\"text\":\"(:22) K.Cousins pass short right to J.Jefferson to MIN 28 for 7 yards (J.Jones).\",\"clock\":{\"displayValue\":\"0:22\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.577,\"playId\":\"401220303867\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":1},\"homeScore\":0,\"awayScore\":9,\"start\":{\"distance\":0,\"yardLine\":0,\"down\":2,\"yardsToEndzone\":72},\"text\":\"END QUARTER 1\",\"clock\":{\"displayValue\":\"0:00\"},\"type\":{\"id\":\"2\",\"text\":\"End Period\",\"abbreviation\":\"EP\"}},\"homeWinPercentage\":0.574,\"playId\":\"401220303891\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":0,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"2nd & 3\",\"possessionText\":\"MIN 28\",\"downDistanceText\":\"2nd & 3 at MIN 28\",\"distance\":3,\"yardLine\":28,\"team\":{\"id\":\"16\"},\"down\":2,\"yardsToEndzone\":72},\"text\":\"(15:00) D.Cook left end to MIN 29 for 1 yard (M.Jack; D.Costin).\",\"clock\":{\"displayValue\":\"15:00\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.559,\"playId\":\"401220303910\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":0,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"3rd & 2\",\"possessionText\":\"MIN 29\",\"downDistanceText\":\"3rd & 2 at MIN 29\",\"distance\":2,\"yardLine\":29,\"team\":{\"id\":\"16\"},\"down\":3,\"yardsToEndzone\":71},\"text\":\"(14:22) (Shotgun) K.Cousins pass incomplete short right to A.Thielen (G.Mabin).\",\"clock\":{\"displayValue\":\"14:22\"},\"type\":{\"id\":\"3\",\"text\":\"Pass Incompletion\"}},\"homeWinPercentage\":0.489,\"playId\":\"401220303931\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":0,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"4th & 2\",\"possessionText\":\"MIN 29\",\"downDistanceText\":\"4th & 2 at MIN 29\",\"distance\":2,\"yardLine\":29,\"team\":{\"id\":\"16\"},\"down\":4,\"yardsToEndzone\":71},\"text\":\"(14:17) B.Colquitt punts 46 yards to JAX 25, Center-A.DePaola, downed by MIN-K.Boyd.\",\"clock\":{\"displayValue\":\"14:17\"},\"type\":{\"id\":\"52\",\"text\":\"Punt\",\"abbreviation\":\"PUNT\"}},\"homeWinPercentage\":0.5,\"playId\":\"401220303953\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":0,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"JAX 25\",\"downDistanceText\":\"1st & 10 at JAX 25\",\"distance\":10,\"yardLine\":75,\"team\":{\"id\":\"30\"},\"down\":1,\"yardsToEndzone\":75},\"text\":\"(14:06) J.Robinson left guard to JAX 28 for 3 yards (T.Davis; J.Johnson).\",\"clock\":{\"displayValue\":\"14:06\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.493,\"playId\":\"401220303972\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":0,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"2nd & 7\",\"possessionText\":\"JAX 28\",\"downDistanceText\":\"2nd & 7 at JAX 28\",\"distance\":7,\"yardLine\":72,\"team\":{\"id\":\"30\"},\"down\":2,\"yardsToEndzone\":72},\"text\":\"(13:27) (Shotgun) M.Glennon pass short left to L.Shenault Jr. to JAX 35 for 7 yards (H.Smith; E.Wilson).\",\"clock\":{\"displayValue\":\"13:27\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.474,\"playId\":\"401220303993\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":0,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"JAX 35\",\"downDistanceText\":\"1st & 10 at JAX 35\",\"distance\":10,\"yardLine\":65,\"team\":{\"id\":\"30\"},\"down\":1,\"yardsToEndzone\":65},\"text\":\"(12:50) M.Glennon pass incomplete deep left to D.Chark Jr..\",\"clock\":{\"displayValue\":\"12:50\"},\"type\":{\"id\":\"3\",\"text\":\"Pass Incompletion\"}},\"homeWinPercentage\":0.507,\"playId\":\"4012203031017\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":0,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"2nd & 10\",\"possessionText\":\"JAX 35\",\"downDistanceText\":\"2nd & 10 at JAX 35\",\"distance\":10,\"yardLine\":65,\"team\":{\"id\":\"30\"},\"down\":2,\"yardsToEndzone\":65},\"text\":\"(12:44) (Shotgun) M.Glennon pass short right to C.Johnson to JAX 41 for 6 yards (H.Smith).\",\"clock\":{\"displayValue\":\"12:44\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.519,\"playId\":\"4012203031039\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":0,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"3rd & 4\",\"possessionText\":\"JAX 41\",\"downDistanceText\":\"3rd & 4 at JAX 41\",\"distance\":4,\"yardLine\":59,\"team\":{\"id\":\"30\"},\"down\":3,\"yardsToEndzone\":59},\"text\":\"(12:03) (Shotgun) M.Glennon pass short left to T.Eifert to JAX 47 for 6 yards (C.Jones).\",\"clock\":{\"displayValue\":\"12:03\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.439,\"playId\":\"4012203031063\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":0,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"JAX 47\",\"downDistanceText\":\"1st & 10 at JAX 47\",\"distance\":10,\"yardLine\":53,\"team\":{\"id\":\"30\"},\"down\":1,\"yardsToEndzone\":53},\"text\":\"(11:24) J.Robinson right end to 50 for 3 yards (T.Davis; A.Watts).\",\"clock\":{\"displayValue\":\"11:24\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.458,\"playId\":\"4012203031087\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":0,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"2nd & 7\",\"possessionText\":\"50\",\"downDistanceText\":\"2nd & 7 at 50\",\"distance\":7,\"yardLine\":50,\"team\":{\"id\":\"30\"},\"down\":2,\"yardsToEndzone\":50},\"text\":\"(10:43) (Shotgun) L.Shenault Jr. right end to MIN 33 for 17 yards (A.Harris).\",\"clock\":{\"displayValue\":\"10:43\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.388,\"playId\":\"4012203031108\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":0,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"MIN 33\",\"downDistanceText\":\"1st & 10 at MIN 33\",\"distance\":10,\"yardLine\":33,\"team\":{\"id\":\"30\"},\"down\":1,\"yardsToEndzone\":33},\"text\":\"(10:02) PENALTY on JAX-J.Taylor, False Start, 5 yards, enforced at MIN 33 - No Play.\",\"clock\":{\"displayValue\":\"10:02\"},\"type\":{\"id\":\"8\",\"text\":\"Penalty\",\"abbreviation\":\"PEN\"}},\"homeWinPercentage\":0.444,\"playId\":\"4012203031132\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":0,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"1st & 15\",\"possessionText\":\"MIN 38\",\"downDistanceText\":\"1st & 15 at MIN 38\",\"distance\":15,\"yardLine\":38,\"team\":{\"id\":\"30\"},\"down\":1,\"yardsToEndzone\":38},\"text\":\"(9:38) (Shotgun) D.Ogunbowale left end to MIN 34 for 4 yards (E.Yarbrough).\",\"clock\":{\"displayValue\":\"9:38\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.419,\"playId\":\"4012203031159\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":0,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"2nd & 11\",\"possessionText\":\"MIN 34\",\"downDistanceText\":\"2nd & 11 at MIN 34\",\"distance\":11,\"yardLine\":34,\"team\":{\"id\":\"30\"},\"down\":2,\"yardsToEndzone\":34},\"text\":\"(8:58) (Shotgun) M.Glennon pass incomplete short left to D.Ogunbowale.\",\"clock\":{\"displayValue\":\"8:58\"},\"type\":{\"id\":\"3\",\"text\":\"Pass Incompletion\"}},\"homeWinPercentage\":0.427,\"playId\":\"4012203031181\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":0,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"3rd & 11\",\"possessionText\":\"MIN 34\",\"downDistanceText\":\"3rd & 11 at MIN 34\",\"distance\":11,\"yardLine\":34,\"team\":{\"id\":\"30\"},\"down\":3,\"yardsToEndzone\":34},\"text\":\"(8:55) (Shotgun) M.Glennon pass short right to T.Eifert to MIN 21 for 13 yards (E.Wilson).\",\"clock\":{\"displayValue\":\"8:55\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.486,\"playId\":\"4012203031203\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":0,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"MIN 21\",\"downDistanceText\":\"1st & 10 at MIN 21\",\"distance\":10,\"yardLine\":21,\"team\":{\"id\":\"30\"},\"down\":1,\"yardsToEndzone\":21},\"text\":\"(8:16) (Shotgun) J.Robinson right tackle to MIN 16 for 5 yards (C.Jones; A.Harris). PENALTY on JAX-L.Shenault Jr., Illegal Shift, 5 yards, enforced at MIN 21 - No Play.\",\"clock\":{\"displayValue\":\"8:16\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.386,\"playId\":\"4012203031227\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":0,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"1st & 15\",\"possessionText\":\"MIN 26\",\"downDistanceText\":\"1st & 15 at MIN 26\",\"distance\":15,\"yardLine\":26,\"team\":{\"id\":\"30\"},\"down\":1,\"yardsToEndzone\":26},\"text\":\"(7:46) (Shotgun) M.Glennon pass short left intended for E.Saubert INTERCEPTED by C.Dantzler at MIN 22. C.Dantzler to MIN 22 for no gain (E.Saubert).\",\"clock\":{\"displayValue\":\"7:46\"},\"type\":{\"id\":\"26\",\"text\":\"Pass Interception Return\",\"abbreviation\":\"INTR\"}},\"homeWinPercentage\":0.495,\"playId\":\"4012203031259\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":0,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"MIN 22\",\"downDistanceText\":\"1st & 10 at MIN 22\",\"distance\":10,\"yardLine\":22,\"team\":{\"id\":\"16\"},\"down\":1,\"yardsToEndzone\":78},\"text\":\"(7:40) D.Cook left tackle to MIN 26 for 4 yards (J.Jones).\",\"clock\":{\"displayValue\":\"7:40\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.502,\"playId\":\"4012203031285\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":0,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"2nd & 6\",\"possessionText\":\"MIN 26\",\"downDistanceText\":\"2nd & 6 at MIN 26\",\"distance\":6,\"yardLine\":26,\"team\":{\"id\":\"16\"},\"down\":2,\"yardsToEndzone\":74},\"text\":\"(7:12) K.Cousins pass short right to A.Thielen pushed ob at MIN 40 for 14 yards (G.Mabin).\",\"clock\":{\"displayValue\":\"7:12\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.524,\"playId\":\"4012203031306\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":0,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"MIN 40\",\"downDistanceText\":\"1st & 10 at MIN 40\",\"distance\":10,\"yardLine\":40,\"team\":{\"id\":\"16\"},\"down\":1,\"yardsToEndzone\":60},\"text\":\"(6:41) D.Cook right tackle to MIN 44 for 4 yards (D.Costin; J.Giles-Harris).\",\"clock\":{\"displayValue\":\"6:41\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.507,\"playId\":\"4012203031335\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":0,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"2nd & 6\",\"possessionText\":\"MIN 44\",\"downDistanceText\":\"2nd & 6 at MIN 44\",\"distance\":6,\"yardLine\":44,\"team\":{\"id\":\"16\"},\"down\":2,\"yardsToEndzone\":56},\"text\":\"(6:07) K.Cousins pass short right to D.Cook to JAX 45 for 11 yards (J.Giles-Harris).\",\"clock\":{\"displayValue\":\"6:07\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.542,\"playId\":\"4012203031356\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":0,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"JAX 45\",\"downDistanceText\":\"1st & 10 at JAX 45\",\"distance\":10,\"yardLine\":55,\"team\":{\"id\":\"16\"},\"down\":1,\"yardsToEndzone\":45},\"text\":\"(5:27) K.Cousins scrambles left end to JAX 35 for 10 yards (G.Mabin).\",\"clock\":{\"displayValue\":\"5:27\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.556,\"playId\":\"4012203031380\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":0,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"JAX 35\",\"downDistanceText\":\"1st & 10 at JAX 35\",\"distance\":10,\"yardLine\":65,\"team\":{\"id\":\"16\"},\"down\":1,\"yardsToEndzone\":35},\"text\":\"(4:47) K.Cousins pass short right to A.Thielen pushed ob at JAX 23 for 12 yards (G.Mabin).\",\"clock\":{\"displayValue\":\"4:47\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.58,\"playId\":\"4012203031401\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":0,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"JAX 23\",\"downDistanceText\":\"1st & 10 at JAX 23\",\"distance\":10,\"yardLine\":77,\"team\":{\"id\":\"16\"},\"down\":1,\"yardsToEndzone\":23},\"text\":\"(4:16) K.Cousins pass incomplete deep left to K.Rudolph [J.Giles-Harris].\",\"clock\":{\"displayValue\":\"4:16\"},\"type\":{\"id\":\"3\",\"text\":\"Pass Incompletion\"}},\"homeWinPercentage\":0.543,\"playId\":\"4012203031430\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":0,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"2nd & 10\",\"possessionText\":\"JAX 23\",\"downDistanceText\":\"2nd & 10 at JAX 23\",\"distance\":10,\"yardLine\":77,\"team\":{\"id\":\"16\"},\"down\":2,\"yardsToEndzone\":23},\"text\":\"(4:10) (Shotgun) K.Cousins pass short middle to D.Cook pushed ob at JAX 3 for 20 yards (M.Jack).\",\"clock\":{\"displayValue\":\"4:10\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.485,\"playId\":\"4012203031452\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":0,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"1st & Goal\",\"possessionText\":\"JAX 3\",\"downDistanceText\":\"1st & Goal at JAX 3\",\"distance\":3,\"yardLine\":97,\"team\":{\"id\":\"16\"},\"down\":1,\"yardsToEndzone\":3},\"text\":\"(3:37) D.Cook left tackle to JAX 3 for no gain (J.Jones; J.Giles-Harris).\",\"clock\":{\"displayValue\":\"3:37\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.61,\"playId\":\"4012203031476\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":6,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"2nd & Goal\",\"possessionText\":\"JAX 3\",\"downDistanceText\":\"2nd & Goal at JAX 3\",\"distance\":3,\"yardLine\":97,\"team\":{\"id\":\"16\"},\"down\":2,\"yardsToEndzone\":3},\"text\":\"Adam Thielen 3 Yd pass from Kirk Cousins (Dan Bailey PAT failed)\",\"clock\":{\"displayValue\":\"2:50\"},\"type\":{\"id\":\"67\",\"text\":\"Passing Touchdown\",\"abbreviation\":\"TD\"}},\"homeWinPercentage\":0.608,\"playId\":\"4012203031497\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":6,\"awayScore\":9,\"start\":{\"distance\":0,\"yardLine\":35,\"team\":{\"id\":\"16\"},\"down\":0,\"yardsToEndzone\":65},\"text\":\"D.Bailey kicks 65 yards from MIN 35 to end zone, Touchback.\",\"clock\":{\"displayValue\":\"2:50\"},\"type\":{\"id\":\"53\",\"text\":\"Kickoff\",\"abbreviation\":\"K\"}},\"homeWinPercentage\":0.601,\"playId\":\"4012203031538\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":6,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"JAX 25\",\"downDistanceText\":\"1st & 10 at JAX 25\",\"distance\":10,\"yardLine\":75,\"team\":{\"id\":\"30\"},\"down\":1,\"yardsToEndzone\":75},\"text\":\"(2:50) (Shotgun) M.Glennon pass incomplete short middle to D.Ogunbowale [I.Odenigbo].\",\"clock\":{\"displayValue\":\"2:50\"},\"type\":{\"id\":\"3\",\"text\":\"Pass Incompletion\"}},\"homeWinPercentage\":0.635,\"playId\":\"4012203031553\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":6,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"2nd & 10\",\"possessionText\":\"JAX 25\",\"downDistanceText\":\"2nd & 10 at JAX 25\",\"distance\":10,\"yardLine\":75,\"team\":{\"id\":\"30\"},\"down\":2,\"yardsToEndzone\":75},\"text\":\"(2:46) (Shotgun) M.Glennon pass short right to J.Robinson to JAX 31 for 6 yards (T.Davis).\",\"clock\":{\"displayValue\":\"2:46\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.62,\"playId\":\"4012203031575\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":6,\"awayScore\":9,\"start\":{\"distance\":4,\"yardLine\":69,\"team\":{\"id\":\"30\"},\"down\":3,\"yardsToEndzone\":69},\"text\":\"Two-Minute Warning\",\"clock\":{\"displayValue\":\"2:00\"},\"type\":{\"id\":\"75\",\"text\":\"Two-minute warning\",\"abbreviation\":\"2Min Warn\"}},\"homeWinPercentage\":0.616,\"playId\":\"4012203031599\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":6,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"3rd & 4\",\"possessionText\":\"JAX 31\",\"downDistanceText\":\"3rd & 4 at JAX 31\",\"distance\":4,\"yardLine\":69,\"team\":{\"id\":\"30\"},\"down\":3,\"yardsToEndzone\":69},\"text\":\"(2:00) (Shotgun) M.Glennon pass short left to L.Shenault Jr. to JAX 34 for 3 yards (I.Odenigbo; E.Wilson).\",\"clock\":{\"displayValue\":\"2:00\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.657,\"playId\":\"4012203031622\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":6,\"awayScore\":9,\"start\":{\"distance\":1,\"yardLine\":66,\"team\":{\"id\":\"30\"},\"down\":4,\"yardsToEndzone\":66},\"text\":\"Timeout #1 by MIN at 01:54.\",\"clock\":{\"displayValue\":\"1:54\"},\"type\":{\"id\":\"21\",\"text\":\"Timeout\",\"abbreviation\":\"TO\"}},\"homeWinPercentage\":0.645,\"playId\":\"4012203031646\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":6,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"4th & 1\",\"possessionText\":\"JAX 34\",\"downDistanceText\":\"4th & 1 at JAX 34\",\"distance\":1,\"yardLine\":66,\"team\":{\"id\":\"30\"},\"down\":4,\"yardsToEndzone\":66},\"text\":\"(1:54) L.Cooke punts 48 yards to MIN 18, Center-R.Matiscik. K.Osborn to MIN 26 for 8 yards (B.Watson).\",\"clock\":{\"displayValue\":\"1:54\"},\"type\":{\"id\":\"52\",\"text\":\"Punt\",\"abbreviation\":\"PUNT\"}},\"homeWinPercentage\":0.641,\"playId\":\"4012203031663\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":6,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"MIN 26\",\"downDistanceText\":\"1st & 10 at MIN 26\",\"distance\":10,\"yardLine\":26,\"team\":{\"id\":\"16\"},\"down\":1,\"yardsToEndzone\":74},\"text\":\"(1:45) (Shotgun) D.Cook left guard to MIN 28 for 2 yards (J.Schobert; C.Reid).\",\"clock\":{\"displayValue\":\"1:45\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.618,\"playId\":\"4012203031688\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":6,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"2nd & 8\",\"possessionText\":\"MIN 28\",\"downDistanceText\":\"2nd & 8 at MIN 28\",\"distance\":8,\"yardLine\":28,\"team\":{\"id\":\"16\"},\"down\":2,\"yardsToEndzone\":72},\"text\":\"(1:28) (No Huddle, Shotgun) PENALTY on JAX-D.Smoot, Neutral Zone Infraction, 5 yards, enforced at MIN 28 - No Play.\",\"clock\":{\"displayValue\":\"1:28\"},\"type\":{\"id\":\"8\",\"text\":\"Penalty\",\"abbreviation\":\"PEN\"}},\"homeWinPercentage\":0.646,\"playId\":\"4012203031709\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":6,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"2nd & 3\",\"possessionText\":\"MIN 33\",\"downDistanceText\":\"2nd & 3 at MIN 33\",\"distance\":3,\"yardLine\":33,\"team\":{\"id\":\"16\"},\"down\":2,\"yardsToEndzone\":67},\"text\":\"(1:28) (Shotgun) K.Cousins pass short left to D.Cook to MIN 38 for 5 yards (T.Herndon) [A.Lynch].\",\"clock\":{\"displayValue\":\"1:28\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.652,\"playId\":\"4012203031732\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":6,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"MIN 38\",\"downDistanceText\":\"1st & 10 at MIN 38\",\"distance\":10,\"yardLine\":38,\"team\":{\"id\":\"16\"},\"down\":1,\"yardsToEndzone\":62},\"text\":\"(1:14) (Shotgun) K.Cousins pass short left to D.Cook to MIN 39 for 1 yard (T.Herndon).\",\"clock\":{\"displayValue\":\"1:14\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.63,\"playId\":\"4012203031756\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":6,\"awayScore\":9,\"start\":{\"distance\":9,\"yardLine\":39,\"team\":{\"id\":\"16\"},\"down\":2,\"yardsToEndzone\":61},\"text\":\"Timeout #2 by MIN at 01:05.\",\"clock\":{\"displayValue\":\"1:05\"},\"type\":{\"id\":\"21\",\"text\":\"Timeout\",\"abbreviation\":\"TO\"}},\"homeWinPercentage\":0.617,\"playId\":\"4012203031780\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":6,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"2nd & 9\",\"possessionText\":\"MIN 39\",\"downDistanceText\":\"2nd & 9 at MIN 39\",\"distance\":9,\"yardLine\":39,\"team\":{\"id\":\"16\"},\"down\":2,\"yardsToEndzone\":61},\"text\":\"(1:05) (Shotgun) PENALTY on MIN-T.Conklin, False Start, 5 yards, enforced at MIN 39 - No Play.\",\"clock\":{\"displayValue\":\"1:05\"},\"type\":{\"id\":\"8\",\"text\":\"Penalty\",\"abbreviation\":\"PEN\"}},\"homeWinPercentage\":0.593,\"playId\":\"4012203031797\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":6,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"2nd & 14\",\"possessionText\":\"MIN 34\",\"downDistanceText\":\"2nd & 14 at MIN 34\",\"distance\":14,\"yardLine\":34,\"team\":{\"id\":\"16\"},\"down\":2,\"yardsToEndzone\":66},\"text\":\"(1:05) (Shotgun) K.Cousins pass short left to C.Beebe pushed ob at MIN 39 for 5 yards (T.Herndon) [K.Chaisson].\",\"clock\":{\"displayValue\":\"1:05\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.603,\"playId\":\"4012203031820\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":6,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"3rd & 9\",\"possessionText\":\"MIN 39\",\"downDistanceText\":\"3rd & 9 at MIN 39\",\"distance\":9,\"yardLine\":39,\"team\":{\"id\":\"16\"},\"down\":3,\"yardsToEndzone\":61},\"text\":\"(1:00) (Shotgun) K.Cousins sacked at MIN 32 for -7 yards (J.Schobert).\",\"clock\":{\"displayValue\":\"1:00\"},\"type\":{\"id\":\"7\",\"text\":\"Sack\"}},\"homeWinPercentage\":0.569,\"playId\":\"4012203031849\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":6,\"awayScore\":9,\"start\":{\"distance\":16,\"yardLine\":32,\"team\":{\"id\":\"16\"},\"down\":4,\"yardsToEndzone\":68},\"text\":\"Timeout #1 by JAX at 00:56.\",\"clock\":{\"displayValue\":\"0:56\"},\"type\":{\"id\":\"21\",\"text\":\"Timeout\",\"abbreviation\":\"TO\"}},\"homeWinPercentage\":0.579,\"playId\":\"4012203031868\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":6,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"4th & 16\",\"possessionText\":\"MIN 32\",\"downDistanceText\":\"4th & 16 at MIN 32\",\"distance\":16,\"yardLine\":32,\"team\":{\"id\":\"16\"},\"down\":4,\"yardsToEndzone\":68},\"text\":\"(:56) B.Colquitt punts 45 yards to JAX 23, Center-A.DePaola, fair catch by K.Cole Sr..\",\"clock\":{\"displayValue\":\"0:56\"},\"type\":{\"id\":\"52\",\"text\":\"Punt\",\"abbreviation\":\"PUNT\"}},\"homeWinPercentage\":0.587,\"playId\":\"4012203031885\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":6,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"JAX 23\",\"downDistanceText\":\"1st & 10 at JAX 23\",\"distance\":10,\"yardLine\":77,\"team\":{\"id\":\"30\"},\"down\":1,\"yardsToEndzone\":77},\"text\":\"(:49) (Shotgun) M.Glennon pass short right to T.Eifert pushed ob at JAX 27 for 4 yards (C.Jones).\",\"clock\":{\"displayValue\":\"0:49\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.695,\"playId\":\"4012203031904\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":6,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"2nd & 6\",\"possessionText\":\"JAX 27\",\"downDistanceText\":\"2nd & 6 at JAX 27\",\"distance\":6,\"yardLine\":73,\"team\":{\"id\":\"30\"},\"down\":2,\"yardsToEndzone\":73},\"text\":\"(:43) (Shotgun) M.Glennon pass short left to J.Robinson ran ob at JAX 32 for 5 yards (C.Dantzler).\",\"clock\":{\"displayValue\":\"0:43\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.583,\"playId\":\"4012203031928\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":6,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"3rd & 1\",\"possessionText\":\"JAX 32\",\"downDistanceText\":\"3rd & 1 at JAX 32\",\"distance\":1,\"yardLine\":68,\"team\":{\"id\":\"30\"},\"down\":3,\"yardsToEndzone\":68},\"text\":\"(:35) (Shotgun) M.Glennon pass incomplete short middle to D.Chark Jr. (H.Smith).\",\"clock\":{\"displayValue\":\"0:35\"},\"type\":{\"id\":\"3\",\"text\":\"Pass Incompletion\"}},\"homeWinPercentage\":0.62,\"playId\":\"4012203031957\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":6,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"4th & 1\",\"possessionText\":\"JAX 32\",\"downDistanceText\":\"4th & 1 at JAX 32\",\"distance\":1,\"yardLine\":68,\"team\":{\"id\":\"30\"},\"down\":4,\"yardsToEndzone\":68},\"text\":\"(:31) L.Cooke punts 47 yards to MIN 21, Center-R.Matiscik, downed by JAX.\",\"clock\":{\"displayValue\":\"0:31\"},\"type\":{\"id\":\"52\",\"text\":\"Punt\",\"abbreviation\":\"PUNT\"}},\"homeWinPercentage\":0.483,\"playId\":\"4012203031979\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":6,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"MIN 21\",\"downDistanceText\":\"1st & 10 at MIN 21\",\"distance\":10,\"yardLine\":21,\"team\":{\"id\":\"16\"},\"down\":1,\"yardsToEndzone\":79},\"text\":\"(:18) K.Cousins pass incomplete short right to C.Beebe (A.Lynch).\",\"clock\":{\"displayValue\":\"0:18\"},\"type\":{\"id\":\"3\",\"text\":\"Pass Incompletion\"}},\"homeWinPercentage\":0.601,\"playId\":\"4012203031999\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":6,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"2nd & 10\",\"possessionText\":\"MIN 21\",\"downDistanceText\":\"2nd & 10 at MIN 21\",\"distance\":10,\"yardLine\":21,\"team\":{\"id\":\"16\"},\"down\":2,\"yardsToEndzone\":79},\"text\":\"(:15) (Shotgun) A.Abdullah right guard to MIN 25 for 4 yards (C.Reid).\",\"clock\":{\"displayValue\":\"0:15\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.603,\"playId\":\"4012203032021\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":6,\"awayScore\":9,\"start\":{\"distance\":6,\"yardLine\":25,\"team\":{\"id\":\"16\"},\"down\":3,\"yardsToEndzone\":75},\"text\":\"Timeout #2 by JAX at 00:10.\",\"clock\":{\"displayValue\":\"0:10\"},\"type\":{\"id\":\"21\",\"text\":\"Timeout\",\"abbreviation\":\"TO\"}},\"homeWinPercentage\":0.606,\"playId\":\"4012203032042\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":6,\"awayScore\":9,\"start\":{\"shortDownDistanceText\":\"3rd & 6\",\"possessionText\":\"MIN 25\",\"downDistanceText\":\"3rd & 6 at MIN 25\",\"distance\":6,\"yardLine\":25,\"team\":{\"id\":\"16\"},\"down\":3,\"yardsToEndzone\":75},\"text\":\"(:10) (Shotgun) A.Abdullah right tackle to MIN 32 for 7 yards (K.Chaisson).\",\"clock\":{\"displayValue\":\"0:10\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.531,\"playId\":\"4012203032059\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":2},\"homeScore\":6,\"awayScore\":9,\"start\":{\"distance\":0,\"yardLine\":0,\"down\":0,\"yardsToEndzone\":0},\"text\":\"END QUARTER 2\",\"clock\":{\"displayValue\":\"0:00\"},\"type\":{\"id\":\"65\",\"text\":\"End of Half\",\"abbreviation\":\"EH\"}},\"homeWinPercentage\":0.644,\"playId\":\"4012203032086\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":3},\"homeScore\":6,\"awayScore\":9,\"start\":{\"distance\":0,\"yardLine\":65,\"team\":{\"id\":\"30\"},\"down\":0,\"yardsToEndzone\":65},\"text\":\"L.Cooke kicks 50 yards from JAX 35 to MIN 15, out of bounds.\",\"clock\":{\"displayValue\":\"15:00\"},\"type\":{\"id\":\"53\",\"text\":\"Kickoff\",\"abbreviation\":\"K\"}},\"homeWinPercentage\":0.673,\"playId\":\"4012203032117\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":3},\"homeScore\":6,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"MIN 40\",\"downDistanceText\":\"1st & 10 at MIN 40\",\"distance\":10,\"yardLine\":40,\"team\":{\"id\":\"16\"},\"down\":1,\"yardsToEndzone\":60},\"text\":\"Joe Schobert 43 Yrd Interception Return C.McLaughlin extra point is GOOD, Center-R.Matiscik, Holder-L.Cooke.\",\"clock\":{\"displayValue\":\"14:50\"},\"type\":{\"id\":\"36\",\"text\":\"Interception Return Touchdown\",\"abbreviation\":\"TD\"}},\"homeWinPercentage\":0.329,\"playId\":\"4012203032143\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":3},\"homeScore\":6,\"awayScore\":16,\"start\":{\"distance\":0,\"yardLine\":65,\"team\":{\"id\":\"30\"},\"down\":0,\"yardsToEndzone\":65},\"text\":\"L.Cooke kicks 65 yards from JAX 35 to end zone, Touchback.\",\"clock\":{\"displayValue\":\"14:50\"},\"type\":{\"id\":\"53\",\"text\":\"Kickoff\",\"abbreviation\":\"K\"}},\"homeWinPercentage\":0.335,\"playId\":\"4012203032186\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":3},\"homeScore\":6,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"MIN 25\",\"downDistanceText\":\"1st & 10 at MIN 25\",\"distance\":10,\"yardLine\":25,\"team\":{\"id\":\"16\"},\"down\":1,\"yardsToEndzone\":75},\"text\":\"(14:50) D.Cook left tackle to MIN 26 for 1 yard (J.Schobert).\",\"clock\":{\"displayValue\":\"14:50\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.311,\"playId\":\"4012203032201\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":3},\"homeScore\":6,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"2nd & 9\",\"possessionText\":\"MIN 26\",\"downDistanceText\":\"2nd & 9 at MIN 26\",\"distance\":9,\"yardLine\":26,\"team\":{\"id\":\"16\"},\"down\":2,\"yardsToEndzone\":74},\"text\":\"(14:21) K.Cousins pass short right to D.Cook pushed ob at MIN 36 for 10 yards (M.Jack).\",\"clock\":{\"displayValue\":\"14:21\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.311,\"playId\":\"4012203032222\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":3},\"homeScore\":6,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"MIN 36\",\"downDistanceText\":\"1st & 10 at MIN 36\",\"distance\":10,\"yardLine\":36,\"team\":{\"id\":\"16\"},\"down\":1,\"yardsToEndzone\":64},\"text\":\"(13:49) D.Cook left end to MIN 36 for no gain (J.Schobert; D.Costin).\",\"clock\":{\"displayValue\":\"13:49\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.323,\"playId\":\"4012203032246\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":3},\"homeScore\":6,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"2nd & 10\",\"possessionText\":\"MIN 36\",\"downDistanceText\":\"2nd & 10 at MIN 36\",\"distance\":10,\"yardLine\":36,\"team\":{\"id\":\"16\"},\"down\":2,\"yardsToEndzone\":64},\"text\":\"(13:14) K.Cousins pass incomplete short right to D.Cook [J.Giles-Harris].\",\"clock\":{\"displayValue\":\"13:14\"},\"type\":{\"id\":\"3\",\"text\":\"Pass Incompletion\"}},\"homeWinPercentage\":0.299,\"playId\":\"4012203032267\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":3},\"homeScore\":6,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"3rd & 10\",\"possessionText\":\"MIN 36\",\"downDistanceText\":\"3rd & 10 at MIN 36\",\"distance\":10,\"yardLine\":36,\"team\":{\"id\":\"16\"},\"down\":3,\"yardsToEndzone\":64},\"text\":\"(13:10) (Shotgun) K.Cousins pass to A.Thielen to MIN 47 for 11 yards (L.Barcoo).\",\"clock\":{\"displayValue\":\"13:10\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.363,\"playId\":\"4012203032289\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":3},\"homeScore\":6,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"MIN 47\",\"downDistanceText\":\"1st & 10 at MIN 47\",\"distance\":10,\"yardLine\":47,\"team\":{\"id\":\"16\"},\"down\":1,\"yardsToEndzone\":53},\"text\":\"(12:32) M.Boone up the middle to 50 for 3 yards (A.Gotsis). PENALTY on MIN-B.O'Neill, Offensive Holding, 10 yards, enforced at MIN 47 - No Play.\",\"clock\":{\"displayValue\":\"12:32\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.333,\"playId\":\"4012203032319\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":3},\"homeScore\":6,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"1st & 20\",\"possessionText\":\"MIN 37\",\"downDistanceText\":\"1st & 20 at MIN 37\",\"distance\":20,\"yardLine\":37,\"team\":{\"id\":\"16\"},\"down\":1,\"yardsToEndzone\":63},\"text\":\"(12:13) K.Cousins pass short right to J.Jefferson to MIN 48 for 11 yards (L.Barcoo).\",\"clock\":{\"displayValue\":\"12:13\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.328,\"playId\":\"4012203032351\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":3},\"homeScore\":6,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"2nd & 9\",\"possessionText\":\"MIN 48\",\"downDistanceText\":\"2nd & 9 at MIN 48\",\"distance\":9,\"yardLine\":48,\"team\":{\"id\":\"16\"},\"down\":2,\"yardsToEndzone\":52},\"text\":\"(11:41) K.Cousins pass deep right to J.Jefferson pushed ob at JAX 12 for 40 yards (L.Barcoo). Penalty on JAX-L.Barcoo, Defensive Pass Interference, declined.\",\"clock\":{\"displayValue\":\"11:41\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.282,\"playId\":\"4012203032375\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":3},\"homeScore\":13,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"JAX 12\",\"downDistanceText\":\"1st & 10 at JAX 12\",\"distance\":10,\"yardLine\":88,\"team\":{\"id\":\"16\"},\"down\":1,\"yardsToEndzone\":12},\"text\":\"C.J. Ham Pass From Kirk Cousins for 12 Yrds D.Bailey extra point is GOOD, Center-A.DePaola, Holder-B.Colquitt.\",\"clock\":{\"displayValue\":\"11:08\"},\"type\":{\"id\":\"67\",\"text\":\"Passing Touchdown\",\"abbreviation\":\"TD\"}},\"homeWinPercentage\":0.538,\"playId\":\"4012203032410\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":3},\"homeScore\":13,\"awayScore\":16,\"start\":{\"distance\":0,\"yardLine\":35,\"team\":{\"id\":\"16\"},\"down\":0,\"yardsToEndzone\":65},\"text\":\"D.Bailey kicks 65 yards from MIN 35 to end zone, Touchback.\",\"clock\":{\"displayValue\":\"11:08\"},\"type\":{\"id\":\"53\",\"text\":\"Kickoff\",\"abbreviation\":\"K\"}},\"homeWinPercentage\":0.531,\"playId\":\"4012203032451\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":3},\"homeScore\":13,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"JAX 25\",\"downDistanceText\":\"1st & 10 at JAX 25\",\"distance\":10,\"yardLine\":75,\"team\":{\"id\":\"30\"},\"down\":1,\"yardsToEndzone\":75},\"text\":\"(11:08) J.Robinson right end pushed ob at JAX 30 for 5 yards (H.Smith).\",\"clock\":{\"displayValue\":\"11:08\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.521,\"playId\":\"4012203032466\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":3},\"homeScore\":13,\"awayScore\":16,\"start\":{\"distance\":5,\"yardLine\":70,\"team\":{\"id\":\"30\"},\"down\":2,\"yardsToEndzone\":70},\"text\":\"Timeout #1 by JAX at 10:28.\",\"clock\":{\"displayValue\":\"10:28\"},\"type\":{\"id\":\"21\",\"text\":\"Timeout\",\"abbreviation\":\"TO\"}},\"homeWinPercentage\":0.536,\"playId\":\"4012203032493\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":3},\"homeScore\":13,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"2nd & 5\",\"possessionText\":\"JAX 30\",\"downDistanceText\":\"2nd & 5 at JAX 30\",\"distance\":5,\"yardLine\":70,\"team\":{\"id\":\"30\"},\"down\":2,\"yardsToEndzone\":70},\"text\":\"(10:28) M.Glennon pass short right to J.Robinson to JAX 36 for 6 yards (K.Boyd).\",\"clock\":{\"displayValue\":\"10:28\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.513,\"playId\":\"4012203032510\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":3},\"homeScore\":13,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"JAX 36\",\"downDistanceText\":\"1st & 10 at JAX 36\",\"distance\":10,\"yardLine\":64,\"team\":{\"id\":\"30\"},\"down\":1,\"yardsToEndzone\":64},\"text\":\"(9:47) J.Robinson left end pushed ob at JAX 42 for 6 yards (C.Dantzler).\",\"clock\":{\"displayValue\":\"9:47\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.498,\"playId\":\"4012203032534\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":3},\"homeScore\":13,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"2nd & 4\",\"possessionText\":\"JAX 42\",\"downDistanceText\":\"2nd & 4 at JAX 42\",\"distance\":4,\"yardLine\":58,\"team\":{\"id\":\"30\"},\"down\":2,\"yardsToEndzone\":58},\"text\":\"(9:23) (Shotgun) M.Glennon pass short right to J.O'Shaughnessy to JAX 48 for 6 yards (E.Wilson; J.Gladney).\",\"clock\":{\"displayValue\":\"9:23\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.475,\"playId\":\"4012203032566\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":3},\"homeScore\":13,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"JAX 48\",\"downDistanceText\":\"1st & 10 at JAX 48\",\"distance\":10,\"yardLine\":52,\"team\":{\"id\":\"30\"},\"down\":1,\"yardsToEndzone\":52},\"text\":\"(8:47) J.Robinson up the middle to 50 for 2 yards (E.Yarbrough; S.Stephen).\",\"clock\":{\"displayValue\":\"8:47\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.552,\"playId\":\"4012203032590\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":3},\"homeScore\":13,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"2nd & 8\",\"possessionText\":\"50\",\"downDistanceText\":\"2nd & 8 at 50\",\"distance\":8,\"yardLine\":50,\"team\":{\"id\":\"30\"},\"down\":2,\"yardsToEndzone\":90},\"text\":\"(8:09) (Shotgun) M.Glennon pass incomplete deep right to C.Johnson.\",\"clock\":{\"displayValue\":\"8:09\"},\"type\":{\"id\":\"3\",\"text\":\"Pass Incompletion\"}},\"homeWinPercentage\":0.615,\"playId\":\"4012203032611\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":3},\"homeScore\":13,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"3rd & 8\",\"possessionText\":\"50\",\"downDistanceText\":\"3rd & 8 at 50\",\"distance\":8,\"yardLine\":50,\"team\":{\"id\":\"30\"},\"down\":3,\"yardsToEndzone\":50},\"text\":\"(8:04) (Shotgun) M.Glennon sacked at JAX 40 for -10 yards (sack split by H.Smith and H.Mata'afa).\",\"clock\":{\"displayValue\":\"8:04\"},\"type\":{\"id\":\"7\",\"text\":\"Sack\"}},\"homeWinPercentage\":0.556,\"playId\":\"4012203032633\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":3},\"homeScore\":13,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"4th & 18\",\"possessionText\":\"JAX 40\",\"downDistanceText\":\"4th & 18 at JAX 40\",\"distance\":18,\"yardLine\":60,\"team\":{\"id\":\"30\"},\"down\":4,\"yardsToEndzone\":60},\"text\":\"(7:26) L.Cooke punts 60 yards to end zone, Center-R.Matiscik, Touchback. PENALTY on MIN-K.Boyd, Illegal Block Above the Waist, 10 yards, enforced at MIN 20.\",\"clock\":{\"displayValue\":\"7:26\"},\"type\":{\"id\":\"52\",\"text\":\"Punt\",\"abbreviation\":\"PUNT\"}},\"homeWinPercentage\":0.477,\"playId\":\"4012203032652\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":3},\"homeScore\":13,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"MIN 10\",\"downDistanceText\":\"1st & 10 at MIN 10\",\"distance\":10,\"yardLine\":10,\"team\":{\"id\":\"16\"},\"down\":1,\"yardsToEndzone\":90},\"text\":\"(7:17) D.Cook right end pushed ob at MIN 20 for 10 yards (J.Jones).\",\"clock\":{\"displayValue\":\"7:17\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.544,\"playId\":\"4012203032680\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":3},\"homeScore\":13,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"MIN 20\",\"downDistanceText\":\"1st & 10 at MIN 20\",\"distance\":10,\"yardLine\":20,\"team\":{\"id\":\"16\"},\"down\":1,\"yardsToEndzone\":80},\"text\":\"(6:50) K.Cousins pass short left to A.Thielen to MIN 29 for 9 yards (M.Jack).\",\"clock\":{\"displayValue\":\"6:50\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.575,\"playId\":\"4012203032706\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":3},\"homeScore\":13,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"2nd & 1\",\"possessionText\":\"MIN 29\",\"downDistanceText\":\"2nd & 1 at MIN 29\",\"distance\":1,\"yardLine\":29,\"team\":{\"id\":\"16\"},\"down\":2,\"yardsToEndzone\":71},\"text\":\"(6:12) K.Cousins up the middle to MIN 31 for 2 yards (C.Reid).\",\"clock\":{\"displayValue\":\"6:12\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.561,\"playId\":\"4012203032730\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":3},\"homeScore\":13,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"MIN 31\",\"downDistanceText\":\"1st & 10 at MIN 31\",\"distance\":10,\"yardLine\":31,\"team\":{\"id\":\"16\"},\"down\":1,\"yardsToEndzone\":69},\"text\":\"(5:38) K.Cousins pass incomplete deep left to J.Jefferson (T.Herndon) [J.Jones]. PENALTY on JAX-J.Jones, Roughing the Passer, 15 yards, enforced at MIN 31 - No Play.\",\"clock\":{\"displayValue\":\"5:38\"},\"type\":{\"id\":\"3\",\"text\":\"Pass Incompletion\"}},\"homeWinPercentage\":0.588,\"playId\":\"4012203032751\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":3},\"homeScore\":13,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"MIN 46\",\"downDistanceText\":\"1st & 10 at MIN 46\",\"distance\":10,\"yardLine\":46,\"team\":{\"id\":\"16\"},\"down\":1,\"yardsToEndzone\":54},\"text\":\"(5:31) D.Cook left end to MIN 47 for 1 yard (J.Schobert).\",\"clock\":{\"displayValue\":\"5:31\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.559,\"playId\":\"4012203032784\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":3},\"homeScore\":13,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"2nd & 9\",\"possessionText\":\"MIN 47\",\"downDistanceText\":\"2nd & 9 at MIN 47\",\"distance\":9,\"yardLine\":47,\"team\":{\"id\":\"16\"},\"down\":2,\"yardsToEndzone\":53},\"text\":\"(4:58) K.Cousins pass incomplete short left to J.Jefferson (D.Costin) [J.Giles-Harris].\",\"clock\":{\"displayValue\":\"4:58\"},\"type\":{\"id\":\"3\",\"text\":\"Pass Incompletion\"}},\"homeWinPercentage\":0.534,\"playId\":\"4012203032805\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":3},\"homeScore\":13,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"3rd & 9\",\"possessionText\":\"MIN 47\",\"downDistanceText\":\"3rd & 9 at MIN 47\",\"distance\":9,\"yardLine\":47,\"team\":{\"id\":\"16\"},\"down\":3,\"yardsToEndzone\":53},\"text\":\"(4:53) (Shotgun) K.Cousins pass short middle to A.Thielen to JAX 41 for 12 yards (J.Jones) [D.Smoot].\",\"clock\":{\"displayValue\":\"4:53\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.477,\"playId\":\"4012203032827\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":3},\"homeScore\":13,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"JAX 41\",\"downDistanceText\":\"1st & 10 at JAX 41\",\"distance\":10,\"yardLine\":59,\"team\":{\"id\":\"16\"},\"down\":1,\"yardsToEndzone\":41},\"text\":\"(4:14) D.Cook right end to JAX 38 for 3 yards (D.Costin; M.Jack).\",\"clock\":{\"displayValue\":\"4:14\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.592,\"playId\":\"4012203032851\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":3},\"homeScore\":13,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"2nd & 7\",\"possessionText\":\"JAX 38\",\"downDistanceText\":\"2nd & 7 at JAX 38\",\"distance\":7,\"yardLine\":62,\"team\":{\"id\":\"16\"},\"down\":2,\"yardsToEndzone\":38},\"text\":\"(3:40) K.Cousins pass incomplete deep right to J.Jefferson [A.Gotsis]. PENALTY on JAX-L.Barcoo, Defensive Pass Interference, 18 yards, enforced at JAX 38 - No Play.\",\"clock\":{\"displayValue\":\"3:40\"},\"type\":{\"id\":\"3\",\"text\":\"Pass Incompletion\"}},\"homeWinPercentage\":0.67,\"playId\":\"4012203032872\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":3},\"homeScore\":19,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"JAX 20\",\"downDistanceText\":\"1st & 10 at JAX 20\",\"distance\":10,\"yardLine\":80,\"team\":{\"id\":\"16\"},\"down\":1,\"yardsToEndzone\":20},\"text\":\"Justin Jefferson 20 Yd pass from Kirk Cousins (Dan Bailey PAT failed)\",\"clock\":{\"displayValue\":\"3:27\"},\"type\":{\"id\":\"67\",\"text\":\"Passing Touchdown\",\"abbreviation\":\"TD\"}},\"homeWinPercentage\":0.729,\"playId\":\"4012203032905\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":3},\"homeScore\":19,\"awayScore\":16,\"start\":{\"distance\":0,\"yardLine\":35,\"team\":{\"id\":\"16\"},\"down\":0,\"yardsToEndzone\":65},\"text\":\"D.Bailey kicks 65 yards from MIN 35 to end zone, Touchback.\",\"clock\":{\"displayValue\":\"3:27\"},\"type\":{\"id\":\"53\",\"text\":\"Kickoff\",\"abbreviation\":\"K\"}},\"homeWinPercentage\":0.722,\"playId\":\"4012203032946\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":3},\"homeScore\":19,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"JAX 25\",\"downDistanceText\":\"1st & 10 at JAX 25\",\"distance\":10,\"yardLine\":75,\"team\":{\"id\":\"30\"},\"down\":1,\"yardsToEndzone\":75},\"text\":\"(3:27) M.Glennon pass incomplete deep left to C.Johnson.\",\"clock\":{\"displayValue\":\"3:27\"},\"type\":{\"id\":\"3\",\"text\":\"Pass Incompletion\"}},\"homeWinPercentage\":0.749,\"playId\":\"4012203032961\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":3},\"homeScore\":19,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"2nd & 10\",\"possessionText\":\"JAX 25\",\"downDistanceText\":\"2nd & 10 at JAX 25\",\"distance\":10,\"yardLine\":75,\"team\":{\"id\":\"30\"},\"down\":2,\"yardsToEndzone\":75},\"text\":\"(3:22) (Shotgun) M.Glennon pass short right to C.Johnson to JAX 30 for 5 yards (K.Boyd).\",\"clock\":{\"displayValue\":\"3:22\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.739,\"playId\":\"4012203032983\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":3},\"homeScore\":19,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"3rd & 5\",\"possessionText\":\"JAX 30\",\"downDistanceText\":\"3rd & 5 at JAX 30\",\"distance\":5,\"yardLine\":70,\"team\":{\"id\":\"30\"},\"down\":3,\"yardsToEndzone\":70},\"text\":\"(2:43) (Shotgun) M.Glennon scrambles right end to JAX 32 for 2 yards (J.Brailford). FUMBLES (J.Brailford), RECOVERED by MIN-J.Brailford at JAX 34.\",\"clock\":{\"displayValue\":\"2:43\"},\"type\":{\"id\":\"29\",\"text\":\"Fumble Recovery (Opponent)\"}},\"homeWinPercentage\":0.834,\"playId\":\"4012203033007\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":3},\"homeScore\":19,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"JAX 34\",\"downDistanceText\":\"1st & 10 at JAX 34\",\"distance\":10,\"yardLine\":66,\"team\":{\"id\":\"16\"},\"down\":1,\"yardsToEndzone\":34},\"text\":\"(2:24) K.Cousins pass incomplete short right [A.Gotsis].\",\"clock\":{\"displayValue\":\"2:24\"},\"type\":{\"id\":\"3\",\"text\":\"Pass Incompletion\"}},\"homeWinPercentage\":0.813,\"playId\":\"4012203033044\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":3},\"homeScore\":19,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"2nd & 10\",\"possessionText\":\"JAX 34\",\"downDistanceText\":\"2nd & 10 at JAX 34\",\"distance\":10,\"yardLine\":66,\"team\":{\"id\":\"16\"},\"down\":2,\"yardsToEndzone\":34},\"text\":\"(2:19) D.Cook right end pushed ob at JAX 22 for 12 yards (J.Wilson).\",\"clock\":{\"displayValue\":\"2:19\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.726,\"playId\":\"4012203033066\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":3},\"homeScore\":19,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"JAX 22\",\"downDistanceText\":\"1st & 10 at JAX 22\",\"distance\":10,\"yardLine\":78,\"team\":{\"id\":\"16\"},\"down\":1,\"yardsToEndzone\":22},\"text\":\"(1:50) K.Cousins pass short right to A.Thielen to JAX 17 for 5 yards (L.Barcoo).\",\"clock\":{\"displayValue\":\"1:50\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.735,\"playId\":\"4012203033097\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":3},\"homeScore\":19,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"2nd & 5\",\"possessionText\":\"JAX 17\",\"downDistanceText\":\"2nd & 5 at JAX 17\",\"distance\":5,\"yardLine\":83,\"team\":{\"id\":\"16\"},\"down\":2,\"yardsToEndzone\":17},\"text\":\"(1:16) D.Cook left guard to JAX 11 for 6 yards (J.Giles-Harris).\",\"clock\":{\"displayValue\":\"1:16\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.882,\"playId\":\"4012203033121\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":3},\"homeScore\":19,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"JAX 11\",\"downDistanceText\":\"1st & 10 at JAX 11\",\"distance\":10,\"yardLine\":89,\"team\":{\"id\":\"16\"},\"down\":1,\"yardsToEndzone\":11},\"text\":\"(:38) D.Cook up the middle to JAX 1 for 10 yards (J.Wilson; J.Schobert).\",\"clock\":{\"displayValue\":\"0:38\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.9,\"playId\":\"4012203033142\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":3},\"homeScore\":19,\"awayScore\":16,\"start\":{\"distance\":0,\"yardLine\":0,\"down\":1,\"yardsToEndzone\":1},\"text\":\"END QUARTER 3\",\"clock\":{\"displayValue\":\"0:00\"},\"type\":{\"id\":\"2\",\"text\":\"End Period\",\"abbreviation\":\"EP\"}},\"homeWinPercentage\":0.902,\"playId\":\"4012203033163\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":19,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"1st & Goal\",\"possessionText\":\"JAX 1\",\"downDistanceText\":\"1st & Goal at JAX 1\",\"distance\":1,\"yardLine\":99,\"team\":{\"id\":\"16\"},\"down\":1,\"yardsToEndzone\":1},\"text\":\"(15:00) K.Cousins FUMBLES (Aborted) at JAX 4, RECOVERED by JAX-M.Jack at JAX 2.\",\"clock\":{\"displayValue\":\"15:00\"},\"type\":{\"id\":\"29\",\"text\":\"Fumble Recovery (Opponent)\"}},\"homeWinPercentage\":0.76,\"playId\":\"4012203033182\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":19,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"JAX 2\",\"downDistanceText\":\"1st & 10 at JAX 2\",\"distance\":10,\"yardLine\":98,\"team\":{\"id\":\"30\"},\"down\":1,\"yardsToEndzone\":98},\"text\":\"(14:55) J.Robinson up the middle to JAX 5 for 3 yards (J.Gladney). MIN-J.Gladney was injured during the play. JAX-B.Linder was injured during the play.\",\"clock\":{\"displayValue\":\"14:55\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.776,\"playId\":\"4012203033223\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":19,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"2nd & 7\",\"possessionText\":\"JAX 5\",\"downDistanceText\":\"2nd & 7 at JAX 5\",\"distance\":7,\"yardLine\":95,\"team\":{\"id\":\"30\"},\"down\":2,\"yardsToEndzone\":95},\"text\":\"(14:33) J.Robinson left end to JAX 4 for -1 yards (A.Harris). FUMBLES (A.Harris), RECOVERED by MIN-A.Harris at JAX 4. A.Harris to JAX 2 for 2 yards (E.Saubert). The Replay Official reviewed the fumble ruling, and the play was REVERSED. J.Robinson left end to JAX 4 for -1 yards (A.Harris).\",\"clock\":{\"displayValue\":\"14:33\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.797,\"playId\":\"4012203033257\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":21,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"3rd & 8\",\"possessionText\":\"JAX 4\",\"downDistanceText\":\"3rd & 8 at JAX 4\",\"distance\":8,\"yardLine\":96,\"team\":{\"id\":\"30\"},\"down\":3,\"yardsToEndzone\":96},\"text\":\"Ifeadi Odenigbo Safety\",\"clock\":{\"displayValue\":\"14:11\"},\"type\":{\"id\":\"20\",\"text\":\"Safety\",\"abbreviation\":\"SF\"}},\"homeWinPercentage\":0.887,\"playId\":\"4012203033335\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":21,\"awayScore\":16,\"start\":{\"distance\":0,\"yardLine\":24,\"team\":{\"id\":\"30\"},\"down\":0,\"yardsToEndzone\":80},\"text\":\"L.Cooke kicks 56 yards from JAX 20 to MIN 24. K.Osborn to MIN 38 for 14 yards (Q.Williams; D.Middleton).\",\"clock\":{\"displayValue\":\"14:11\"},\"type\":{\"id\":\"12\",\"text\":\"Kickoff Return (Offense)\"}},\"homeWinPercentage\":0.851,\"playId\":\"4012203033354\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":21,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"MIN 38\",\"downDistanceText\":\"1st & 10 at MIN 38\",\"distance\":10,\"yardLine\":38,\"team\":{\"id\":\"16\"},\"down\":1,\"yardsToEndzone\":62},\"text\":\"(14:05) D.Cook up the middle to MIN 41 for 3 yards (D.Smoot).\",\"clock\":{\"displayValue\":\"14:05\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.837,\"playId\":\"4012203033379\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":21,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"2nd & 7\",\"possessionText\":\"MIN 41\",\"downDistanceText\":\"2nd & 7 at MIN 41\",\"distance\":7,\"yardLine\":41,\"team\":{\"id\":\"16\"},\"down\":2,\"yardsToEndzone\":59},\"text\":\"(13:29) D.Cook up the middle to MIN 41 for no gain (M.Jack).\",\"clock\":{\"displayValue\":\"13:29\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.822,\"playId\":\"4012203033400\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":21,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"3rd & 7\",\"possessionText\":\"MIN 41\",\"downDistanceText\":\"3rd & 7 at MIN 41\",\"distance\":7,\"yardLine\":41,\"team\":{\"id\":\"16\"},\"down\":3,\"yardsToEndzone\":59},\"text\":\"(12:52) (Shotgun) K.Cousins pass short left to J.Jefferson to JAX 45 for 14 yards (J.Jones).\",\"clock\":{\"displayValue\":\"12:52\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.877,\"playId\":\"4012203033421\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":21,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"JAX 45\",\"downDistanceText\":\"1st & 10 at JAX 45\",\"distance\":10,\"yardLine\":55,\"team\":{\"id\":\"16\"},\"down\":1,\"yardsToEndzone\":45},\"text\":\"(12:14) D.Cook left guard to JAX 44 for 1 yard (K.Chaisson; M.Jack).\",\"clock\":{\"displayValue\":\"12:14\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.853,\"playId\":\"4012203033445\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":21,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"2nd & 9\",\"possessionText\":\"JAX 44\",\"downDistanceText\":\"2nd & 9 at JAX 44\",\"distance\":9,\"yardLine\":56,\"team\":{\"id\":\"16\"},\"down\":2,\"yardsToEndzone\":44},\"text\":\"(11:34) K.Cousins pass short left to J.Jefferson to JAX 40 for 4 yards (T.Herndon).\",\"clock\":{\"displayValue\":\"11:34\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.858,\"playId\":\"4012203033466\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":21,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"3rd & 5\",\"possessionText\":\"JAX 40\",\"downDistanceText\":\"3rd & 5 at JAX 40\",\"distance\":5,\"yardLine\":60,\"team\":{\"id\":\"16\"},\"down\":3,\"yardsToEndzone\":40},\"text\":\"(10:50) (Shotgun) K.Cousins pass incomplete deep right to J.Jefferson.\",\"clock\":{\"displayValue\":\"10:50\"},\"type\":{\"id\":\"3\",\"text\":\"Pass Incompletion\"}},\"homeWinPercentage\":0.81,\"playId\":\"4012203033490\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":21,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"4th & 5\",\"possessionText\":\"JAX 40\",\"downDistanceText\":\"4th & 5 at JAX 40\",\"distance\":5,\"yardLine\":60,\"team\":{\"id\":\"16\"},\"down\":4,\"yardsToEndzone\":40},\"text\":\"(10:45) B.Colquitt punts 40 yards to end zone, Center-A.DePaola, Touchback.\",\"clock\":{\"displayValue\":\"10:45\"},\"type\":{\"id\":\"52\",\"text\":\"Punt\",\"abbreviation\":\"PUNT\"}},\"homeWinPercentage\":0.796,\"playId\":\"4012203033512\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":21,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"JAX 20\",\"downDistanceText\":\"1st & 10 at JAX 20\",\"distance\":10,\"yardLine\":80,\"team\":{\"id\":\"30\"},\"down\":1,\"yardsToEndzone\":80},\"text\":\"(10:32) J.Robinson left end to JAX 22 for 2 yards (H.Hand).\",\"clock\":{\"displayValue\":\"10:32\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.813,\"playId\":\"4012203033529\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":21,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"2nd & 8\",\"possessionText\":\"JAX 22\",\"downDistanceText\":\"2nd & 8 at JAX 22\",\"distance\":8,\"yardLine\":78,\"team\":{\"id\":\"30\"},\"down\":2,\"yardsToEndzone\":78},\"text\":\"(9:58) (Shotgun) M.Glennon pass incomplete short middle to J.O'Shaughnessy (E.Wilson).\",\"clock\":{\"displayValue\":\"9:58\"},\"type\":{\"id\":\"3\",\"text\":\"Pass Incompletion\"}},\"homeWinPercentage\":0.828,\"playId\":\"4012203033550\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":21,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"3rd & 8\",\"possessionText\":\"JAX 22\",\"downDistanceText\":\"3rd & 8 at JAX 22\",\"distance\":8,\"yardLine\":78,\"team\":{\"id\":\"30\"},\"down\":3,\"yardsToEndzone\":78},\"text\":\"(9:51) (Shotgun) M.Glennon pass short left to T.Eifert to JAX 28 for 6 yards (K.Boyd; T.Davis).\",\"clock\":{\"displayValue\":\"9:51\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.848,\"playId\":\"4012203033572\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":21,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"4th & 2\",\"possessionText\":\"JAX 28\",\"downDistanceText\":\"4th & 2 at JAX 28\",\"distance\":2,\"yardLine\":72,\"team\":{\"id\":\"30\"},\"down\":4,\"yardsToEndzone\":72},\"text\":\"(9:13) L.Cooke punts 44 yards to MIN 28, Center-R.Matiscik. K.Osborn to MIN 34 for 6 yards (Q.Williams; R.Matiscik). FUMBLES (Q.Williams), and recovers at MIN 34.\",\"clock\":{\"displayValue\":\"9:13\"},\"type\":{\"id\":\"52\",\"text\":\"Punt\",\"abbreviation\":\"PUNT\"}},\"homeWinPercentage\":0.66,\"playId\":\"4012203033596\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":21,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"MIN 34\",\"downDistanceText\":\"1st & 10 at MIN 34\",\"distance\":10,\"yardLine\":34,\"team\":{\"id\":\"16\"},\"down\":1,\"yardsToEndzone\":66},\"text\":\"(9:02) D.Cook up the middle to MIN 35 for 1 yard (D.Ekuale).\",\"clock\":{\"displayValue\":\"9:02\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.664,\"playId\":\"4012203033637\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":21,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"2nd & 9\",\"possessionText\":\"MIN 35\",\"downDistanceText\":\"2nd & 9 at MIN 35\",\"distance\":9,\"yardLine\":35,\"team\":{\"id\":\"16\"},\"down\":2,\"yardsToEndzone\":65},\"text\":\"(8:23) K.Cousins sacked at MIN 26 for -9 yards (D.Ekuale).\",\"clock\":{\"displayValue\":\"8:23\"},\"type\":{\"id\":\"7\",\"text\":\"Sack\"}},\"homeWinPercentage\":0.771,\"playId\":\"4012203033658\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":21,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"3rd & 18\",\"possessionText\":\"MIN 26\",\"downDistanceText\":\"3rd & 18 at MIN 26\",\"distance\":18,\"yardLine\":26,\"team\":{\"id\":\"16\"},\"down\":3,\"yardsToEndzone\":74},\"text\":\"(7:41) (Shotgun) D.Cook up the middle to MIN 33 for 7 yards (A.Lynch).\",\"clock\":{\"displayValue\":\"7:41\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.774,\"playId\":\"4012203033677\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":21,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"4th & 11\",\"possessionText\":\"MIN 33\",\"downDistanceText\":\"4th & 11 at MIN 33\",\"distance\":11,\"yardLine\":33,\"team\":{\"id\":\"16\"},\"down\":4,\"yardsToEndzone\":67},\"text\":\"(7:08) B.Colquitt punts 49 yards to JAX 18, Center-A.DePaola, fair catch by K.Cole Sr..\",\"clock\":{\"displayValue\":\"7:08\"},\"type\":{\"id\":\"52\",\"text\":\"Punt\",\"abbreviation\":\"PUNT\"}},\"homeWinPercentage\":0.802,\"playId\":\"4012203033698\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":21,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"JAX 18\",\"downDistanceText\":\"1st & 10 at JAX 18\",\"distance\":10,\"yardLine\":82,\"team\":{\"id\":\"30\"},\"down\":1,\"yardsToEndzone\":82},\"text\":\"(7:01) M.Glennon pass deep left to D.Chark Jr. to JAX 37 for 19 yards (K.Boyd; E.Wilson).\",\"clock\":{\"displayValue\":\"7:01\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.757,\"playId\":\"4012203033726\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":21,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"JAX 37\",\"downDistanceText\":\"1st & 10 at JAX 37\",\"distance\":10,\"yardLine\":63,\"team\":{\"id\":\"30\"},\"down\":1,\"yardsToEndzone\":63},\"text\":\"(6:26) M.Glennon scrambles up the middle to JAX 41 for 4 yards (E.Wilson).\",\"clock\":{\"displayValue\":\"6:26\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.769,\"playId\":\"4012203033750\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":21,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"2nd & 6\",\"possessionText\":\"JAX 41\",\"downDistanceText\":\"2nd & 6 at JAX 41\",\"distance\":6,\"yardLine\":59,\"team\":{\"id\":\"30\"},\"down\":2,\"yardsToEndzone\":59},\"text\":\"(5:39) M.Glennon pass short right to C.Conley to JAX 45 for 4 yards (C.Dantzler). FUMBLES (C.Dantzler), RECOVERED by MIN-C.Dantzler at JAX 44. C.Dantzler to JAX 44 for no gain (J.O'Shaughnessy).\",\"clock\":{\"displayValue\":\"5:39\"},\"type\":{\"id\":\"29\",\"text\":\"Fumble Recovery (Opponent)\"}},\"homeWinPercentage\":0.902,\"playId\":\"4012203033771\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":21,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"JAX 44\",\"downDistanceText\":\"1st & 10 at JAX 44\",\"distance\":10,\"yardLine\":56,\"team\":{\"id\":\"16\"},\"down\":1,\"yardsToEndzone\":44},\"text\":\"(5:29) K.Cousins pass short right to J.Jefferson to JAX 33 for 11 yards (T.Herndon).\",\"clock\":{\"displayValue\":\"5:29\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.923,\"playId\":\"4012203033811\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":21,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"JAX 33\",\"downDistanceText\":\"1st & 10 at JAX 33\",\"distance\":10,\"yardLine\":67,\"team\":{\"id\":\"16\"},\"down\":1,\"yardsToEndzone\":33},\"text\":\"(4:49) D.Cook left tackle to JAX 30 for 3 yards (J.Schobert; M.Jack).\",\"clock\":{\"displayValue\":\"4:49\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.922,\"playId\":\"4012203033835\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":21,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"2nd & 7\",\"possessionText\":\"JAX 30\",\"downDistanceText\":\"2nd & 7 at JAX 30\",\"distance\":7,\"yardLine\":70,\"team\":{\"id\":\"16\"},\"down\":2,\"yardsToEndzone\":30},\"text\":\"(4:08) K.Cousins pass incomplete short right [J.Giles-Harris].\",\"clock\":{\"displayValue\":\"4:08\"},\"type\":{\"id\":\"3\",\"text\":\"Pass Incompletion\"}},\"homeWinPercentage\":0.916,\"playId\":\"4012203033856\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":21,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"3rd & 7\",\"possessionText\":\"JAX 30\",\"downDistanceText\":\"3rd & 7 at JAX 30\",\"distance\":7,\"yardLine\":70,\"team\":{\"id\":\"16\"},\"down\":3,\"yardsToEndzone\":15},\"text\":\"(4:01) (Shotgun) K.Cousins pass incomplete deep left to J.Jefferson (T.Herndon) [J.Schobert].\",\"clock\":{\"displayValue\":\"4:01\"},\"type\":{\"id\":\"3\",\"text\":\"Pass Incompletion\"}},\"homeWinPercentage\":0.776,\"playId\":\"4012203033878\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":24,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"4th & 7\",\"possessionText\":\"JAX 30\",\"downDistanceText\":\"4th & 7 at JAX 30\",\"distance\":7,\"yardLine\":70,\"team\":{\"id\":\"16\"},\"down\":4,\"yardsToEndzone\":30},\"text\":\"Dan Bailey 48 Yd Field Goal\",\"clock\":{\"displayValue\":\"3:50\"},\"type\":{\"id\":\"59\",\"text\":\"Field Goal Good\",\"abbreviation\":\"FG\"}},\"homeWinPercentage\":0.94,\"playId\":\"4012203033900\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":24,\"awayScore\":16,\"start\":{\"distance\":0,\"yardLine\":35,\"team\":{\"id\":\"16\"},\"down\":0,\"yardsToEndzone\":65},\"text\":\"D.Bailey kicks 65 yards from MIN 35 to end zone, Touchback.\",\"clock\":{\"displayValue\":\"3:50\"},\"type\":{\"id\":\"53\",\"text\":\"Kickoff\",\"abbreviation\":\"K\"}},\"homeWinPercentage\":0.936,\"playId\":\"4012203033919\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":24,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"JAX 25\",\"downDistanceText\":\"1st & 10 at JAX 25\",\"distance\":10,\"yardLine\":75,\"team\":{\"id\":\"30\"},\"down\":1,\"yardsToEndzone\":75},\"text\":\"(3:50) (Shotgun) M.Glennon pass short middle to K.Cole Sr. to JAX 32 for 7 yards (E.Wilson).\",\"clock\":{\"displayValue\":\"3:50\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.919,\"playId\":\"4012203033934\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":24,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"2nd & 3\",\"possessionText\":\"JAX 32\",\"downDistanceText\":\"2nd & 3 at JAX 32\",\"distance\":3,\"yardLine\":68,\"team\":{\"id\":\"30\"},\"down\":2,\"yardsToEndzone\":68},\"text\":\"(3:29) (No Huddle, Shotgun) M.Glennon pass short left to J.Robinson to JAX 36 for 4 yards (E.Wilson; A.Harris).\",\"clock\":{\"displayValue\":\"3:29\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.918,\"playId\":\"4012203033958\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":24,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"JAX 36\",\"downDistanceText\":\"1st & 10 at JAX 36\",\"distance\":10,\"yardLine\":64,\"team\":{\"id\":\"30\"},\"down\":1,\"yardsToEndzone\":64},\"text\":\"(2:56) (No Huddle, Shotgun) M.Glennon pass short right to T.Eifert to JAX 46 for 10 yards (C.Dantzler; T.Davis).\",\"clock\":{\"displayValue\":\"2:56\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.905,\"playId\":\"4012203033982\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":24,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"JAX 46\",\"downDistanceText\":\"1st & 10 at JAX 46\",\"distance\":10,\"yardLine\":54,\"team\":{\"id\":\"30\"},\"down\":1,\"yardsToEndzone\":54},\"text\":\"(2:29) (No Huddle, Shotgun) M.Glennon pass incomplete deep right to D.Chark Jr..\",\"clock\":{\"displayValue\":\"2:29\"},\"type\":{\"id\":\"3\",\"text\":\"Pass Incompletion\"}},\"homeWinPercentage\":0.928,\"playId\":\"4012203034006\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":24,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"2nd & 10\",\"possessionText\":\"JAX 46\",\"downDistanceText\":\"2nd & 10 at JAX 46\",\"distance\":10,\"yardLine\":54,\"team\":{\"id\":\"30\"},\"down\":2,\"yardsToEndzone\":54},\"text\":\"(2:23) (Shotgun) M.Glennon pass short left to C.Conley to MIN 45 for 9 yards (T.Davis; K.Boyd).\",\"clock\":{\"displayValue\":\"2:23\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.887,\"playId\":\"4012203034028\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":24,\"awayScore\":16,\"start\":{\"distance\":1,\"yardLine\":45,\"team\":{\"id\":\"30\"},\"down\":3,\"yardsToEndzone\":45},\"text\":\"Two-Minute Warning\",\"clock\":{\"displayValue\":\"2:00\"},\"type\":{\"id\":\"75\",\"text\":\"Two-minute warning\",\"abbreviation\":\"2Min Warn\"}},\"homeWinPercentage\":0.9,\"playId\":\"4012203034052\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":24,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"3rd & 1\",\"possessionText\":\"MIN 45\",\"downDistanceText\":\"3rd & 1 at MIN 45\",\"distance\":1,\"yardLine\":45,\"team\":{\"id\":\"30\"},\"down\":3,\"yardsToEndzone\":45},\"text\":\"(2:00) PENALTY on JAX-J.Taylor, False Start, 5 yards, enforced at MIN 45 - No Play.\",\"clock\":{\"displayValue\":\"2:00\"},\"type\":{\"id\":\"8\",\"text\":\"Penalty\",\"abbreviation\":\"PEN\"}},\"homeWinPercentage\":0.932,\"playId\":\"4012203034069\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":24,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"3rd & 6\",\"possessionText\":\"50\",\"downDistanceText\":\"3rd & 6 at 50\",\"distance\":6,\"yardLine\":50,\"team\":{\"id\":\"30\"},\"down\":3,\"yardsToEndzone\":50},\"text\":\"(2:00) (Shotgun) M.Glennon pass deep left to D.Chark Jr. pushed ob at MIN 28 for 22 yards (H.Hand).\",\"clock\":{\"displayValue\":\"2:00\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.977,\"playId\":\"4012203034092\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":24,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"MIN 28\",\"downDistanceText\":\"1st & 10 at MIN 28\",\"distance\":10,\"yardLine\":28,\"team\":{\"id\":\"30\"},\"down\":1,\"yardsToEndzone\":28},\"text\":\"(1:53) (Shotgun) M.Glennon scrambles left end ran ob at MIN 25 for 3 yards (H.Mata'afa).\",\"clock\":{\"displayValue\":\"1:53\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.881,\"playId\":\"4012203034116\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":24,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"2nd & 7\",\"possessionText\":\"MIN 25\",\"downDistanceText\":\"2nd & 7 at MIN 25\",\"distance\":7,\"yardLine\":25,\"team\":{\"id\":\"30\"},\"down\":2,\"yardsToEndzone\":25},\"text\":\"(1:46) (Shotgun) M.Glennon pass deep right to C.Johnson to MIN 4 for 21 yards (H.Smith).\",\"clock\":{\"displayValue\":\"1:46\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.771,\"playId\":\"4012203034142\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":24,\"awayScore\":16,\"start\":{\"shortDownDistanceText\":\"1st & Goal\",\"possessionText\":\"MIN 4\",\"downDistanceText\":\"1st & Goal at MIN 4\",\"distance\":4,\"yardLine\":4,\"team\":{\"id\":\"30\"},\"down\":1,\"yardsToEndzone\":4},\"text\":\"(1:18) (No Huddle, Shotgun) D.Ogunbowale up the middle to MIN 1 for 3 yards (J.Brailford).\",\"clock\":{\"displayValue\":\"1:18\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.766,\"playId\":\"4012203034166\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":24,\"awayScore\":16,\"start\":{\"distance\":1,\"yardLine\":1,\"team\":{\"id\":\"30\"},\"down\":2,\"yardsToEndzone\":1},\"text\":\"Timeout #1 by MIN at 01:12.\",\"clock\":{\"displayValue\":\"1:12\"},\"type\":{\"id\":\"21\",\"text\":\"Timeout\",\"abbreviation\":\"TO\"}},\"homeWinPercentage\":0.77,\"playId\":\"4012203034187\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":24,\"awayScore\":24,\"start\":{\"shortDownDistanceText\":\"2nd & Goal\",\"possessionText\":\"MIN 1\",\"downDistanceText\":\"2nd & Goal at MIN 1\",\"distance\":1,\"yardLine\":1,\"team\":{\"id\":\"30\"},\"down\":2,\"yardsToEndzone\":1},\"text\":\"James Robinson 1 Yard Rush (Pass formation) TWO-POINT CONVERSION ATTEMPT. M.Glennon pass to C.Johnson is complete. ATTEMPT SUCCEEDS.\",\"clock\":{\"displayValue\":\"1:08\"},\"type\":{\"id\":\"68\",\"text\":\"Rushing Touchdown\",\"abbreviation\":\"TD\"}},\"homeWinPercentage\":0.521,\"playId\":\"4012203034204\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":24,\"awayScore\":24,\"start\":{\"distance\":0,\"yardLine\":65,\"team\":{\"id\":\"30\"},\"down\":0,\"yardsToEndzone\":65},\"text\":\"L.Cooke kicks 65 yards from JAX 35 to end zone, Touchback.\",\"clock\":{\"displayValue\":\"1:08\"},\"type\":{\"id\":\"53\",\"text\":\"Kickoff\",\"abbreviation\":\"K\"}},\"homeWinPercentage\":0.551,\"playId\":\"4012203034263\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":24,\"awayScore\":24,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"MIN 25\",\"downDistanceText\":\"1st & 10 at MIN 25\",\"distance\":10,\"yardLine\":25,\"team\":{\"id\":\"16\"},\"down\":1,\"yardsToEndzone\":75},\"text\":\"(1:08) (Shotgun) D.Cook right end pushed ob at MIN 29 for 4 yards (J.Scott; J.Schobert).\",\"clock\":{\"displayValue\":\"1:08\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.414,\"playId\":\"4012203034278\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":24,\"awayScore\":24,\"start\":{\"shortDownDistanceText\":\"2nd & 6\",\"possessionText\":\"MIN 29\",\"downDistanceText\":\"2nd & 6 at MIN 29\",\"distance\":6,\"yardLine\":29,\"team\":{\"id\":\"16\"},\"down\":2,\"yardsToEndzone\":71},\"text\":\"(1:03) (Shotgun) K.Cousins pass short left to C.Beebe pushed ob at MIN 34 for 5 yards (T.Herndon).\",\"clock\":{\"displayValue\":\"1:03\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.442,\"playId\":\"4012203034299\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":24,\"awayScore\":24,\"start\":{\"shortDownDistanceText\":\"3rd & 1\",\"possessionText\":\"MIN 34\",\"downDistanceText\":\"3rd & 1 at MIN 34\",\"distance\":1,\"yardLine\":34,\"team\":{\"id\":\"16\"},\"down\":3,\"yardsToEndzone\":66},\"text\":\"(:58) (Shotgun) D.Cook up the middle to MIN 40 for 6 yards (J.Wilson).\",\"clock\":{\"displayValue\":\"0:58\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.643,\"playId\":\"4012203034323\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":24,\"awayScore\":24,\"start\":{\"distance\":10,\"yardLine\":40,\"team\":{\"id\":\"16\"},\"down\":1,\"yardsToEndzone\":60},\"text\":\"Timeout #2 by MIN at 00:53.\",\"clock\":{\"displayValue\":\"0:53\"},\"type\":{\"id\":\"21\",\"text\":\"Timeout\",\"abbreviation\":\"TO\"}},\"homeWinPercentage\":0.618,\"playId\":\"4012203034350\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":24,\"awayScore\":24,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"MIN 40\",\"downDistanceText\":\"1st & 10 at MIN 40\",\"distance\":10,\"yardLine\":40,\"team\":{\"id\":\"16\"},\"down\":1,\"yardsToEndzone\":60},\"text\":\"(:53) (Shotgun) K.Cousins pass short middle to A.Abdullah to JAX 42 for 18 yards (J.Scott).\",\"clock\":{\"displayValue\":\"0:53\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.737,\"playId\":\"4012203034367\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":24,\"awayScore\":24,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"JAX 42\",\"downDistanceText\":\"1st & 10 at JAX 42\",\"distance\":10,\"yardLine\":58,\"team\":{\"id\":\"16\"},\"down\":1,\"yardsToEndzone\":42},\"text\":\"(:34) (No Huddle, Shotgun) K.Cousins pass incomplete short left [K.Chaisson].\",\"clock\":{\"displayValue\":\"0:34\"},\"type\":{\"id\":\"3\",\"text\":\"Pass Incompletion\"}},\"homeWinPercentage\":0.64,\"playId\":\"4012203034391\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":24,\"awayScore\":24,\"start\":{\"distance\":10,\"yardLine\":58,\"team\":{\"id\":\"16\"},\"down\":2,\"yardsToEndzone\":42},\"text\":\"Timeout #3 by JAX at 00:29.\",\"clock\":{\"displayValue\":\"0:29\"},\"type\":{\"id\":\"21\",\"text\":\"Timeout\",\"abbreviation\":\"TO\"}},\"homeWinPercentage\":0.642,\"playId\":\"4012203034413\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":24,\"awayScore\":24,\"start\":{\"shortDownDistanceText\":\"2nd & 10\",\"possessionText\":\"JAX 42\",\"downDistanceText\":\"2nd & 10 at JAX 42\",\"distance\":10,\"yardLine\":58,\"team\":{\"id\":\"16\"},\"down\":2,\"yardsToEndzone\":42},\"text\":\"(:29) (Shotgun) K.Cousins pass short right to J.Jefferson to JAX 33 for 9 yards (L.Barcoo).\",\"clock\":{\"displayValue\":\"0:29\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.835,\"playId\":\"4012203034430\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":24,\"awayScore\":24,\"start\":{\"distance\":1,\"yardLine\":67,\"team\":{\"id\":\"16\"},\"down\":3,\"yardsToEndzone\":33},\"text\":\"Timeout #3 by MIN at 00:23.\",\"clock\":{\"displayValue\":\"0:23\"},\"type\":{\"id\":\"21\",\"text\":\"Timeout\",\"abbreviation\":\"TO\"}},\"homeWinPercentage\":0.812,\"playId\":\"4012203034454\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":24,\"awayScore\":24,\"start\":{\"shortDownDistanceText\":\"3rd & 1\",\"possessionText\":\"JAX 33\",\"downDistanceText\":\"3rd & 1 at JAX 33\",\"distance\":1,\"yardLine\":67,\"team\":{\"id\":\"16\"},\"down\":3,\"yardsToEndzone\":33},\"text\":\"(:23) (Shotgun) K.Cousins pass incomplete deep right to A.Thielen (L.Barcoo).\",\"clock\":{\"displayValue\":\"0:23\"},\"type\":{\"id\":\"3\",\"text\":\"Pass Incompletion\"}},\"homeWinPercentage\":0.706,\"playId\":\"4012203034471\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":24,\"awayScore\":24,\"start\":{\"shortDownDistanceText\":\"4th & 1\",\"possessionText\":\"JAX 33\",\"downDistanceText\":\"4th & 1 at JAX 33\",\"distance\":1,\"yardLine\":67,\"team\":{\"id\":\"16\"},\"down\":4,\"yardsToEndzone\":33},\"text\":\"(:18) D.Bailey 51 yard field goal is No Good, Wide Left, Center-A.DePaola, Holder-B.Colquitt.\",\"clock\":{\"displayValue\":\"0:18\"},\"type\":{\"id\":\"60\",\"text\":\"Field Goal Missed\",\"abbreviation\":\"FGM\"}},\"homeWinPercentage\":0.494,\"playId\":\"4012203034493\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":24,\"awayScore\":24,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"JAX 41\",\"downDistanceText\":\"1st & 10 at JAX 41\",\"distance\":10,\"yardLine\":59,\"team\":{\"id\":\"30\"},\"down\":1,\"yardsToEndzone\":59},\"text\":\"(:13) (Shotgun) J.Robinson up the middle to MIN 44 for 15 yards (T.Davis).\",\"clock\":{\"displayValue\":\"0:13\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.452,\"playId\":\"4012203034525\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":24,\"awayScore\":24,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"MIN 44\",\"downDistanceText\":\"1st & 10 at MIN 44\",\"distance\":10,\"yardLine\":44,\"team\":{\"id\":\"30\"},\"down\":1,\"yardsToEndzone\":85},\"text\":\"(:02) M.Glennon spiked the ball to stop the clock.\",\"clock\":{\"displayValue\":\"0:01\"},\"type\":{\"id\":\"3\",\"text\":\"Pass Incompletion\"}},\"homeWinPercentage\":0.5,\"playId\":\"4012203034546\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":24,\"awayScore\":24,\"start\":{\"shortDownDistanceText\":\"2nd & 10\",\"possessionText\":\"MIN 44\",\"downDistanceText\":\"2nd & 10 at MIN 44\",\"distance\":10,\"yardLine\":44,\"team\":{\"id\":\"30\"},\"down\":2,\"yardsToEndzone\":44},\"text\":\"(:01) C.McLaughlin 62 yard field goal is No Good, Short, Center-R.Matiscik, Holder-L.Cooke.\",\"clock\":{\"displayValue\":\"0:01\"},\"type\":{\"id\":\"60\",\"text\":\"Field Goal Missed\",\"abbreviation\":\"FGM\"}},\"homeWinPercentage\":0.502,\"playId\":\"4012203034568\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"period\":{\"number\":4},\"homeScore\":24,\"awayScore\":24,\"start\":{\"distance\":0,\"yardLine\":0,\"down\":0,\"yardsToEndzone\":0},\"text\":\"END QUARTER 4\",\"clock\":{\"displayValue\":\"0:00\"},\"type\":{\"id\":\"79\",\"text\":\"End of Regulation\",\"abbreviation\":\"ER\"}},\"homeWinPercentage\":0.5,\"playId\":\"4012203034588\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"overtimePlayCount\":1,\"period\":{\"number\":5},\"homeScore\":24,\"awayScore\":24,\"start\":{\"distance\":0,\"yardLine\":0,\"team\":{\"id\":\"30\"},\"down\":0,\"yardsToEndzone\":65},\"text\":\"L.Cooke kicks 65 yards from JAX 35 to MIN 0. A.Abdullah to MIN 24 for 24 yards (S.Quarterman; N.Cottrell).\",\"clock\":{\"displayValue\":\"10:00\"},\"type\":{\"id\":\"12\",\"text\":\"Kickoff Return (Offense)\"}},\"homeWinPercentage\":0.546,\"playId\":\"4012203034607\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"overtimePlayCount\":2,\"period\":{\"number\":5},\"homeScore\":24,\"awayScore\":24,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"MIN 24\",\"downDistanceText\":\"1st & 10 at MIN 24\",\"distance\":10,\"yardLine\":24,\"team\":{\"id\":\"16\"},\"down\":1,\"yardsToEndzone\":76},\"text\":\"(9:56) K.Cousins sacked at MIN 15 for -9 yards (D.Smoot).\",\"clock\":{\"displayValue\":\"9:56\"},\"type\":{\"id\":\"7\",\"text\":\"Sack\"}},\"homeWinPercentage\":0.348,\"playId\":\"4012203034629\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"overtimePlayCount\":3,\"period\":{\"number\":5},\"homeScore\":24,\"awayScore\":24,\"start\":{\"shortDownDistanceText\":\"2nd & 19\",\"possessionText\":\"MIN 15\",\"downDistanceText\":\"2nd & 19 at MIN 15\",\"distance\":19,\"yardLine\":15,\"team\":{\"id\":\"16\"},\"down\":2,\"yardsToEndzone\":85},\"text\":\"(9:17) (Shotgun) K.Cousins pass incomplete short middle to K.Rudolph (J.Schobert).\",\"clock\":{\"displayValue\":\"9:17\"},\"type\":{\"id\":\"3\",\"text\":\"Pass Incompletion\"}},\"homeWinPercentage\":0.325,\"playId\":\"4012203034648\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"overtimePlayCount\":4,\"period\":{\"number\":5},\"homeScore\":24,\"awayScore\":24,\"start\":{\"distance\":19,\"yardLine\":15,\"team\":{\"id\":\"16\"},\"down\":3,\"yardsToEndzone\":85},\"text\":\"Timeout #1 by MIN at 09:13.\",\"clock\":{\"displayValue\":\"9:13\"},\"type\":{\"id\":\"21\",\"text\":\"Timeout\",\"abbreviation\":\"TO\"}},\"homeWinPercentage\":0.325,\"playId\":\"4012203034670\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"overtimePlayCount\":5,\"period\":{\"number\":5},\"homeScore\":24,\"awayScore\":24,\"start\":{\"shortDownDistanceText\":\"3rd & 19\",\"possessionText\":\"MIN 15\",\"downDistanceText\":\"3rd & 19 at MIN 15\",\"distance\":19,\"yardLine\":15,\"team\":{\"id\":\"16\"},\"down\":3,\"yardsToEndzone\":85},\"text\":\"(9:13) (Shotgun) K.Cousins pass deep left to J.Jefferson to JAX 38 for 47 yards (J.Wilson) [C.Reid]. PENALTY on MIN-J.Jefferson, Offensive Pass Interference, 7 yards, enforced at MIN 15 - No Play.\",\"clock\":{\"displayValue\":\"9:13\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.255,\"playId\":\"4012203034687\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"overtimePlayCount\":6,\"period\":{\"number\":5},\"homeScore\":24,\"awayScore\":24,\"start\":{\"shortDownDistanceText\":\"3rd & 26\",\"possessionText\":\"MIN 8\",\"downDistanceText\":\"3rd & 26 at MIN 8\",\"distance\":26,\"yardLine\":8,\"team\":{\"id\":\"16\"},\"down\":3,\"yardsToEndzone\":92},\"text\":\"(8:52) (Shotgun) K.Cousins pass short right to D.Cook to MIN 20 for 12 yards (J.Scott).\",\"clock\":{\"displayValue\":\"8:52\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.083,\"playId\":\"4012203034722\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"overtimePlayCount\":7,\"period\":{\"number\":5},\"homeScore\":24,\"awayScore\":24,\"start\":{\"shortDownDistanceText\":\"4th & 14\",\"possessionText\":\"MIN 20\",\"downDistanceText\":\"4th & 14 at MIN 20\",\"distance\":14,\"yardLine\":20,\"team\":{\"id\":\"16\"},\"down\":4,\"yardsToEndzone\":80},\"text\":\"(8:16) B.Colquitt punts 52 yards to JAX 28, Center-A.DePaola. K.Cole Sr. to JAX 29 for 1 yard (D.Chisena). PENALTY on JAX-B.Watson, Offensive Holding, 10 yards, enforced at JAX 28.\",\"clock\":{\"displayValue\":\"8:16\"},\"type\":{\"id\":\"52\",\"text\":\"Punt\",\"abbreviation\":\"PUNT\"}},\"homeWinPercentage\":0.52,\"playId\":\"4012203034746\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"overtimePlayCount\":8,\"period\":{\"number\":5},\"homeScore\":24,\"awayScore\":24,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"JAX 18\",\"downDistanceText\":\"1st & 10 at JAX 18\",\"distance\":10,\"yardLine\":82,\"team\":{\"id\":\"30\"},\"down\":1,\"yardsToEndzone\":82},\"text\":\"(8:06) M.Glennon pass incomplete short right to J.O'Shaughnessy (A.Harris).\",\"clock\":{\"displayValue\":\"8:06\"},\"type\":{\"id\":\"3\",\"text\":\"Pass Incompletion\"}},\"homeWinPercentage\":0.593,\"playId\":\"4012203034782\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"overtimePlayCount\":9,\"period\":{\"number\":5},\"homeScore\":24,\"awayScore\":24,\"start\":{\"shortDownDistanceText\":\"2nd & 10\",\"possessionText\":\"JAX 18\",\"downDistanceText\":\"2nd & 10 at JAX 18\",\"distance\":10,\"yardLine\":82,\"team\":{\"id\":\"30\"},\"down\":2,\"yardsToEndzone\":82},\"text\":\"(8:01) J.Robinson left end to JAX 20 for 2 yards (K.Boyd; H.Hand).\",\"clock\":{\"displayValue\":\"8:01\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.597,\"playId\":\"4012203034804\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"overtimePlayCount\":10,\"period\":{\"number\":5},\"homeScore\":24,\"awayScore\":24,\"start\":{\"shortDownDistanceText\":\"3rd & 8\",\"possessionText\":\"JAX 20\",\"downDistanceText\":\"3rd & 8 at JAX 20\",\"distance\":8,\"yardLine\":80,\"team\":{\"id\":\"30\"},\"down\":3,\"yardsToEndzone\":80},\"text\":\"(7:19) (Shotgun) M.Glennon pass deep middle intended for D.Chark Jr. INTERCEPTED by H.Smith [I.Odenigbo] at JAX 46. H.Smith to JAX 46 for no gain (D.Chark Jr.).\",\"clock\":{\"displayValue\":\"7:19\"},\"type\":{\"id\":\"26\",\"text\":\"Pass Interception Return\",\"abbreviation\":\"INTR\"}},\"homeWinPercentage\":0.764,\"playId\":\"4012203034825\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"overtimePlayCount\":11,\"period\":{\"number\":5},\"homeScore\":24,\"awayScore\":24,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"JAX 46\",\"downDistanceText\":\"1st & 10 at JAX 46\",\"distance\":10,\"yardLine\":54,\"team\":{\"id\":\"16\"},\"down\":1,\"yardsToEndzone\":46},\"text\":\"(7:13) K.Cousins pass short left to A.Thielen to JAX 37 for 9 yards (J.Wilson).\",\"clock\":{\"displayValue\":\"7:13\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.793,\"playId\":\"4012203034851\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"overtimePlayCount\":12,\"period\":{\"number\":5},\"homeScore\":24,\"awayScore\":24,\"start\":{\"shortDownDistanceText\":\"2nd & 1\",\"possessionText\":\"JAX 37\",\"downDistanceText\":\"2nd & 1 at JAX 37\",\"distance\":1,\"yardLine\":63,\"team\":{\"id\":\"16\"},\"down\":2,\"yardsToEndzone\":37},\"text\":\"(6:41) K.Cousins pass incomplete short right to T.Conklin (J.Jones). PENALTY on MIN-J.Jefferson, Offensive Offside, 5 yards, enforced at JAX 37 - No Play.\",\"clock\":{\"displayValue\":\"6:41\"},\"type\":{\"id\":\"3\",\"text\":\"Pass Incompletion\"}},\"homeWinPercentage\":0.719,\"playId\":\"4012203034875\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"overtimePlayCount\":13,\"period\":{\"number\":5},\"homeScore\":24,\"awayScore\":24,\"start\":{\"shortDownDistanceText\":\"2nd & 6\",\"possessionText\":\"JAX 42\",\"downDistanceText\":\"2nd & 6 at JAX 42\",\"distance\":6,\"yardLine\":58,\"team\":{\"id\":\"16\"},\"down\":2,\"yardsToEndzone\":42},\"text\":\"(6:35) K.Cousins pass short middle to T.Conklin to JAX 32 for 10 yards (J.Jones).\",\"clock\":{\"displayValue\":\"6:35\"},\"type\":{\"id\":\"24\",\"text\":\"Pass Reception\",\"abbreviation\":\"REC\"}},\"homeWinPercentage\":0.844,\"playId\":\"4012203034908\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"overtimePlayCount\":14,\"period\":{\"number\":5},\"homeScore\":24,\"awayScore\":24,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"JAX 32\",\"downDistanceText\":\"1st & 10 at JAX 32\",\"distance\":10,\"yardLine\":68,\"team\":{\"id\":\"16\"},\"down\":1,\"yardsToEndzone\":32},\"text\":\"(5:57) D.Cook right guard to JAX 27 for 5 yards (J.Giles-Harris; J.Jones).\",\"clock\":{\"displayValue\":\"5:57\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.883,\"playId\":\"4012203034932\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"overtimePlayCount\":15,\"period\":{\"number\":5},\"homeScore\":24,\"awayScore\":24,\"start\":{\"shortDownDistanceText\":\"2nd & 5\",\"possessionText\":\"JAX 27\",\"downDistanceText\":\"2nd & 5 at JAX 27\",\"distance\":5,\"yardLine\":73,\"team\":{\"id\":\"16\"},\"down\":2,\"yardsToEndzone\":27},\"text\":\"(5:21) D.Cook left end to JAX 28 for -1 yards (J.Schobert; M.Jack).\",\"clock\":{\"displayValue\":\"5:21\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.871,\"playId\":\"4012203034953\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"overtimePlayCount\":16,\"period\":{\"number\":5},\"homeScore\":24,\"awayScore\":24,\"start\":{\"shortDownDistanceText\":\"3rd & 6\",\"possessionText\":\"JAX 28\",\"downDistanceText\":\"3rd & 6 at JAX 28\",\"distance\":6,\"yardLine\":72,\"team\":{\"id\":\"16\"},\"down\":3,\"yardsToEndzone\":28},\"text\":\"(4:38) D.Cook up the middle to JAX 18 for 10 yards (J.Jones).\",\"clock\":{\"displayValue\":\"4:38\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.925,\"playId\":\"4012203034974\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"overtimePlayCount\":17,\"period\":{\"number\":5},\"homeScore\":24,\"awayScore\":24,\"start\":{\"shortDownDistanceText\":\"1st & 10\",\"possessionText\":\"JAX 18\",\"downDistanceText\":\"1st & 10 at JAX 18\",\"distance\":10,\"yardLine\":82,\"team\":{\"id\":\"16\"},\"down\":1,\"yardsToEndzone\":18},\"text\":\"(4:03) D.Cook up the middle to JAX 14 for 4 yards (J.Schobert; T.Herndon).\",\"clock\":{\"displayValue\":\"4:03\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.949,\"playId\":\"4012203034995\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"overtimePlayCount\":18,\"period\":{\"number\":5},\"homeScore\":24,\"awayScore\":24,\"start\":{\"shortDownDistanceText\":\"2nd & 6\",\"possessionText\":\"JAX 14\",\"downDistanceText\":\"2nd & 6 at JAX 14\",\"distance\":6,\"yardLine\":86,\"team\":{\"id\":\"16\"},\"down\":2,\"yardsToEndzone\":14},\"text\":\"(3:28) D.Cook right end to JAX 11 for 3 yards (D.Costin).\",\"clock\":{\"displayValue\":\"3:28\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.966,\"playId\":\"4012203035016\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"overtimePlayCount\":20,\"period\":{\"number\":5},\"homeScore\":24,\"awayScore\":24,\"start\":{\"shortDownDistanceText\":\"3rd & 3\",\"possessionText\":\"JAX 11\",\"downDistanceText\":\"3rd & 3 at JAX 11\",\"distance\":3,\"yardLine\":89,\"team\":{\"id\":\"16\"},\"down\":3,\"yardsToEndzone\":11},\"text\":\"(3:03) D.Cook left guard to JAX 5 for 6 yards (J.Wilson; J.Jones).\",\"clock\":{\"displayValue\":\"3:03\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.981,\"playId\":\"4012203035054\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"overtimePlayCount\":19,\"period\":{\"number\":5},\"homeScore\":24,\"awayScore\":24,\"start\":{\"distance\":5,\"yardLine\":95,\"team\":{\"id\":\"16\"},\"down\":1,\"yardsToEndzone\":5},\"text\":\"Timeout #2 by MIN at 03:03.\",\"clock\":{\"displayValue\":\"3:01\"},\"type\":{\"id\":\"21\",\"text\":\"Timeout\",\"abbreviation\":\"TO\"}},\"homeWinPercentage\":0.966,\"playId\":\"4012203035037\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"overtimePlayCount\":21,\"period\":{\"number\":5},\"homeScore\":24,\"awayScore\":24,\"start\":{\"shortDownDistanceText\":\"1st & Goal\",\"possessionText\":\"JAX 5\",\"downDistanceText\":\"1st & Goal at JAX 5\",\"distance\":5,\"yardLine\":95,\"team\":{\"id\":\"16\"},\"down\":1,\"yardsToEndzone\":5},\"text\":\"(2:27) D.Cook left guard to JAX 2 for 3 yards (J.Schobert).\",\"clock\":{\"displayValue\":\"2:27\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.992,\"playId\":\"4012203035075\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"overtimePlayCount\":22,\"period\":{\"number\":5},\"homeScore\":24,\"awayScore\":24,\"start\":{\"distance\":2,\"yardLine\":98,\"team\":{\"id\":\"16\"},\"down\":2,\"yardsToEndzone\":2},\"text\":\"Two-Minute Warning\",\"clock\":{\"displayValue\":\"2:00\"},\"type\":{\"id\":\"75\",\"text\":\"Two-minute warning\",\"abbreviation\":\"2Min Warn\"}},\"homeWinPercentage\":0.992,\"playId\":\"4012203035096\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"overtimePlayCount\":23,\"period\":{\"number\":5},\"homeScore\":24,\"awayScore\":24,\"start\":{\"shortDownDistanceText\":\"2nd & Goal\",\"possessionText\":\"JAX 2\",\"downDistanceText\":\"2nd & Goal at JAX 2\",\"distance\":2,\"yardLine\":98,\"team\":{\"id\":\"16\"},\"down\":2,\"yardsToEndzone\":2},\"text\":\"(2:00) D.Cook up the middle to JAX 1 for 1 yard (D.Smoot; A.Gotsis).\",\"clock\":{\"displayValue\":\"2:00\"},\"type\":{\"id\":\"5\",\"text\":\"Rush\",\"abbreviation\":\"RUSH\"}},\"homeWinPercentage\":0.996,\"playId\":\"4012203035113\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"overtimePlayCount\":24,\"period\":{\"number\":5},\"homeScore\":24,\"awayScore\":24,\"start\":{\"distance\":1,\"yardLine\":99,\"team\":{\"id\":\"16\"},\"down\":3,\"yardsToEndzone\":1},\"text\":\"Timeout #1 by JAX at 01:53.\",\"clock\":{\"displayValue\":\"1:53\"},\"type\":{\"id\":\"21\",\"text\":\"Timeout\",\"abbreviation\":\"TO\"}},\"homeWinPercentage\":0.996,\"playId\":\"4012203035134\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"overtimePlayCount\":25,\"period\":{\"number\":5},\"homeScore\":24,\"awayScore\":24,\"start\":{\"shortDownDistanceText\":\"3rd & Goal\",\"possessionText\":\"JAX 1\",\"downDistanceText\":\"3rd & Goal at JAX 1\",\"distance\":1,\"yardLine\":99,\"team\":{\"id\":\"16\"},\"down\":3,\"yardsToEndzone\":1},\"text\":\"(1:53) PENALTY on MIN-D.Dozier, False Start, 4 yards, enforced at JAX 1 - No Play.\",\"clock\":{\"displayValue\":\"1:53\"},\"type\":{\"id\":\"8\",\"text\":\"Penalty\",\"abbreviation\":\"PEN\"}},\"homeWinPercentage\":0.987,\"playId\":\"4012203035151\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"overtimePlayCount\":26,\"period\":{\"number\":5},\"homeScore\":27,\"awayScore\":24,\"start\":{\"shortDownDistanceText\":\"3rd & Goal\",\"possessionText\":\"JAX 5\",\"downDistanceText\":\"3rd & Goal at JAX 5\",\"distance\":5,\"yardLine\":95,\"team\":{\"id\":\"16\"},\"down\":3,\"yardsToEndzone\":5},\"text\":\"Dan Bailey 23 Yd Field Goal\",\"clock\":{\"displayValue\":\"1:49\"},\"type\":{\"id\":\"59\",\"text\":\"Field Goal Good\",\"abbreviation\":\"FG\"}},\"homeWinPercentage\":1,\"playId\":\"4012203035174\",\"tiePercentage\":0,\"secondsLeft\":0},{\"play\":{\"overtimePlayCount\":27,\"period\":{\"number\":5},\"homeScore\":27,\"awayScore\":24,\"start\":{\"distance\":0,\"yardLine\":0,\"down\":1,\"yardsToEndzone\":65},\"text\":\"END GAME\",\"clock\":{\"displayValue\":\"0:00\"},\"type\":{\"id\":\"66\",\"text\":\"End of Game\",\"abbreviation\":\"EG\"}},\"homeWinPercentage\":1,\"playId\":\"4012203035193\",\"tiePercentage\":0,\"secondsLeft\":0}];\n\t\t\t\t\t\n\n\t\t\t\t\t\n\n\t\t\t\t\t\t\n\t\t\t\t\t\t\n\t\t\t\t\t\t\n\n\t\t\t\t\t\t\n\n\t\t\t\t\t\tfunction loadScripts() {\n\t\t\t\t\t\t\tvar src = \"https://a.espncdn.com/redesign/0.591.3/js/dist/gamepackage-static.min.js\",\n\t\t\t\t\t\t\t\tscript;\n\t\t\t\t\t\t\t\t\n\t\t\t\t\t\t\tif (espn.gamepackage.status === \"in\") {\n\t\t\t\t\t\t\t\tif (!espn.gamepackage.core) {\n\t\t\t\t\t\t\t\t\tsrc = src.replace(\"gamepackage.\", \"gamepackage.core.\");\n\t\t\t\t\t\t\t\t} else if (espn.gamepackage.bundles && typeof espn.gamepackage.bundles[espn.gamepackage.sport] === \"function\") {\n\t\t\t\t\t\t\t\t\tespn.gamepackage.init();\n\t\t\t\t\t\t\t\t\tespn.gamepackage.bundles[espn.gamepackage.sport]();\n\t\t\t\t\t\t\t\t\treturn;\n\t\t\t\t\t\t\t\t}\n\t\t\t\t\t\t\t} else if (espn.gamepackage.init) {\n\t\t\t\t\t\t\t\tespn.gamepackage.init();\n\t\t\t\t\t\t\t\treturn;\n\t\t\t\t\t\t\t}\n\n\t\t\t\t\t\t\tscript = document.createElement(\"script\");\n\t\t\t\t\t\t\tscript.type = \"text/javascript\";\n\t\t\t\t\t\t\tscript.src = src;\n\t\t\t\t\t\t\tdocument.getElementsByTagName(\"head\")[0].appendChild(script);\n\t\t\t\t\t\t}\n\n\t\t\t\t\t\t\n\t\t\t\t\t\t\tif (window.espn_ui.deferReady === true) {\n\t\t\t\t\t\t\t\t$(document).one(\"page.render\", loadScripts);\n\t\t\t\t\t\t\t} else {\n\t\t\t\t\t\t\t\t$.subscribe(\"espn.defer.end\", loadScripts);\n\t\t\t\t\t\t\t}\n\t\t\t\t\t\t\n\n\t\t\t\t\t\tif( typeof(newrelic) !== \"undefined\" ){\n\t\t\t\t\t\t\tnewrelic.setCustomAttribute( \"game-state\", espn.gamepackage.status );\n\t\t\t\t\t\t}\n\t\t\t\t\t\n\t\t\t\t})(jQuery);\n\t\t\t"Now the short of this is that we have the full script text, so there’s a lot of random JavaScript and logic along with HTML around the actual JSON we want. We want to find the “starting edge” and the end of the JSON file, which should be [{ and }] respectively.
I’ll start by removing all the new lines (\n) and tabs (\t), then finding anything that matches [{ and replace anything before it with [{, followed by the same idea for }].
This should return a raw string of the JSON content, which we can then parse with jsonlite! Regex is #magic, but in short the pattern of ".*(\\[\\{)" finds any text .* ahead of [{ which needs to be escaped as (\\[\\{) and replaces it with the matched component (\\1) which should be [{. We do that for both the start and end of the JSON file, to remove all the extra text and just get the JSON file itself.
raw_json_embed <- example_embed_json %>%
str_remove_all("\\n|\\t") %>%
str_replace(".*(\\[\\{)", "\\1") %>%
str_replace("(\\}\\]).*", "\\1")
ex_parsed_json <- jsonlite::parse_json(raw_json_embed)
ex_parsed_json %>% enframe()# A tibble: 216 × 2
name value
<int> <list>
1 1 <named list [5]>
2 2 <named list [5]>
3 3 <named list [5]>
4 4 <named list [5]>
5 5 <named list [5]>
6 6 <named list [5]>
7 7 <named list [5]>
8 8 <named list [5]>
9 9 <named list [5]>
10 10 <named list [5]>
# … with 206 more rowsESPN’s native API
Now that was a lot of work to just get at the JSON, but I wanted to show an example of where JSON data is embedded into the site. Alternatively, ESPN has a native pseudo-public API that returns the same data!
Let’s use that to get the data instead! (Note the summary below shows the full script if you want to skip ahead).
Full Script
espn_url <- "http://site.api.espn.com/apis/site/v2/sports/football/nfl/summary?event=401220303"
raw_espn_json <- httr::GET(espn_url) %>%
httr::content()
win_pct_df <- raw_espn_json[["winprobability"]] %>%
enframe() %>%
rename(row_id = name) %>%
unnest_wider(value) %>%
janitor::clean_names()
pbp_raw_espn <- raw_espn_json[["drives"]][[1]] %>%
enframe() %>%
unnest_wider(value) %>%
rename(
drive_id = id,
drive_start = start,
drive_end = end
)
pbp_raw_espn_plays <- pbp_raw_espn %>%
unnest_longer(plays) %>%
unnest_wider(plays) %>%
rename(play_id = id)
espn_pbp_clean <- pbp_raw_espn_plays %>%
hoist(
.col = team,
pos_team = "name",
pos_abb = "abbreviation",
pos_full = "displayName",
pos_short = 4 # could also use "shortDisplayName"
) %>%
hoist(
type,
play_type_id = "id",
play_type = "text",
play_type_abb = "abbreviation"
) %>%
hoist(
period,
quarter = "number"
) %>%
hoist(
clock,
clock = "displayValue"
) %>%
janitor::clean_names() %>%
# drop remaining list columns
select(-where(is.list))
espn_joined <- left_join(espn_pbp_clean, win_pct_df, by = "play_id")
final_espn <- espn_joined %>%
mutate(
home_team = raw_espn_json[["boxscore"]][["teams"]][[1]][["team"]][["abbreviation"]],
away_team = raw_espn_json[["boxscore"]][["teams"]][[2]][["team"]][["abbreviation"]]
)final_espn %>%
ggplot(aes(x = row_id, y = 1 - home_win_percentage)) +
geom_line(size = 1) +
scale_y_continuous(breaks = c(0, 0.25, .5, .75, 1), labels = c(100, "", 50, "", 100), limits = c(0, 1)) +
theme_minimal() +
theme(
panel.grid.minor = element_blank(),
panel.grid.major.x = element_blank()
) +
labs(x = "", y = "")Warning: Removed 1 row(s) containing missing values (geom_path).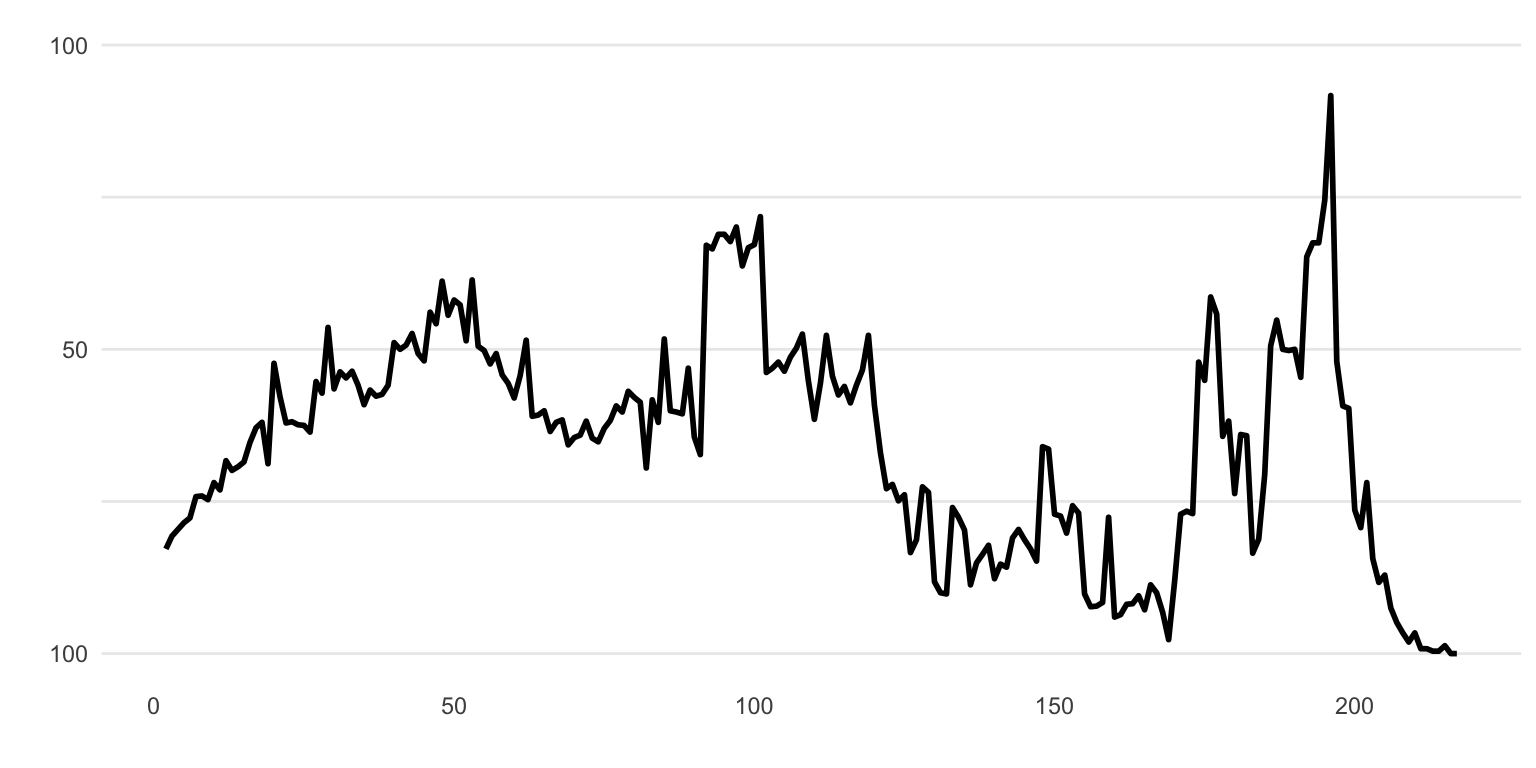
tidyr::hoist()
We’re going to introduce a new tidyr function in this section called hoist(). You can think of tidyr::hoist() as a way of extracting or hoisting specific list column elements into a new named column. This is especially helpful where the JSON has duplicate names, like id which really means game_id and id which really means play_id. With repeated names, unnest_ functions will error or append names as you’re essentially recreating existing columns.
espn_url <- "http://site.api.espn.com/apis/site/v2/sports/football/nfl/summary?event=401220303"
raw_espn_json <- httr::GET(espn_url) %>%
httr::content()
raw_espn_json %>% str(max.level = 1)List of 17
$ boxscore :List of 2
$ format :List of 2
$ gameInfo :List of 3
$ drives :List of 1
$ leaders :List of 2
$ broadcasts : list()
$ predictor :List of 3
$ pickcenter :List of 4
$ againstTheSpread:List of 2
$ odds : list()
$ winprobability :List of 217
$ header :List of 8
$ scoringPlays :List of 10
$ news :List of 3
$ article :List of 22
$ videos : list()
$ standings :List of 2Now I’m most interested in the winprobability data, although you could get all sorts of metadata about simple play-by-play, news, etc. This is a VERY long output, so I’m just going to grab the first few.
[1] 217List of 3
$ :List of 4
..$ tiePercentage : num 0
..$ homeWinPercentage: num 0.832
..$ secondsLeft : int 0
..$ playId : chr "4012203031"
$ :List of 4
..$ tiePercentage : num 0
..$ homeWinPercentage: num 0.828
..$ secondsLeft : int 0
..$ playId : chr "40122030340"
$ :List of 4
..$ tiePercentage : num 0
..$ homeWinPercentage: num 0.807
..$ secondsLeft : int 0
..$ playId : chr "40122030355"Sinec we have a long list of repeated lists of length 4, we can assume that unnest_wider() is the right choice here (4 distinct columns, that are already “long”). We could always rely on unnest_auto() to guess for us and then replace it with the correct function afterwards.
I’m going to stick with my preferred workflow of tibble::enframe() and then unnest_wider.
win_pct_df <- raw_espn_json[["winprobability"]] %>%
enframe() %>%
rename(row_id = name) %>%
unnest_wider(value) %>%
janitor::clean_names()
win_pct_df# A tibble: 217 × 5
row_id tie_percentage home_win_percentage seconds_left play_id
<int> <dbl> <dbl> <int> <chr>
1 1 0 0.832 0 4012203031
2 2 0 0.828 0 40122030340
3 3 0 0.807 0 40122030355
4 4 0 0.796 0 40122030379
5 5 0 0.785 0 401220303108
6 6 0 0.777 0 401220303129
7 7 0 0.742 0 401220303150
8 8 0 0.741 0 401220303191
9 9 0 0.747 0 401220303213
10 10 0 0.719 0 401220303257
# … with 207 more rowsPlay-by-play
Now the other datasets we’re interested in are the drive info (for play-by-play), along with the game info like teams playing, play type, period, and time remaining.
Let’s start with the core JSON data, and then extract the drives data.
List of 17
$ boxscore :List of 2
$ format :List of 2
$ gameInfo :List of 3
$ drives :List of 1
$ leaders :List of 2
$ broadcasts : list()
$ predictor :List of 3
$ pickcenter :List of 4
$ againstTheSpread:List of 2
$ odds : list()
$ winprobability :List of 217
$ header :List of 8
$ scoringPlays :List of 10
$ news :List of 3
$ article :List of 22
$ videos : list()
$ standings :List of 2raw_espn_json[["drives"]][[1]] %>% enframe()# A tibble: 30 × 2
name value
<int> <list>
1 1 <named list [13]>
2 2 <named list [13]>
3 3 <named list [13]>
4 4 <named list [13]>
5 5 <named list [13]>
6 6 <named list [13]>
7 7 <named list [13]>
8 8 <named list [13]>
9 9 <named list [13]>
10 10 <named list [13]>
# … with 20 more rowsAgain we notice that this is already “long” so we can assume we need to unnest_wider(). I’ll also rename a few columns since they’re not very descriptive (and duplicates of other columns).
pbp_raw_espn <- raw_espn_json[["drives"]][[1]] %>%
enframe() %>%
unnest_wider(value) %>%
rename(
drive_id = id,
drive_start = start,
drive_end = end
)
pbp_raw_espn %>% str(max.level = 2)tibble [30 × 14] (S3: tbl_df/tbl/data.frame)
$ name : int [1:30] 1 2 3 4 5 6 7 8 9 10 ...
$ drive_id : chr [1:30] "4012203031" "4012203032" "4012203033" "4012203034" ...
$ description : chr [1:30] "5 plays, 75 yards, 2:27" "3 plays, 12 yards, 1:22" "10 plays, 66 yards, 5:07" "5 plays, 5 yards, 3:08" ...
$ team :List of 30
$ drive_start :List of 30
$ drive_end :List of 30
$ timeElapsed :List of 30
$ yards : int [1:30] 75 12 66 5 16 8 49 78 9 6 ...
$ isScore : logi [1:30] TRUE FALSE TRUE FALSE FALSE FALSE ...
$ offensivePlays : int [1:30] 5 3 10 5 4 3 11 10 3 5 ...
$ result : chr [1:30] "TD" "PUNT" "FG" "PUNT" ...
$ shortDisplayResult: chr [1:30] "TD" "PUNT" "FG" "PUNT" ...
$ displayResult : chr [1:30] "Touchdown" "Punt" "Field Goal" "Punt" ...
$ plays :List of 30Let’s go longer
At this point we can see the data is at the drive level, and the description is the metadata about how long the drive lasted. We want actual plays, and there is a list column named plays. We’ll need to increase the length of the data, so let’s try unnest_longer().
tibble [217 × 14] (S3: tbl_df/tbl/data.frame)
$ name : int [1:217] 1 1 1 1 1 1 2 2 2 2 ...
$ drive_id : chr [1:217] "4012203031" "4012203031" "4012203031" "4012203031" ...
$ description : chr [1:217] "5 plays, 75 yards, 2:27" "5 plays, 75 yards, 2:27" "5 plays, 75 yards, 2:27" "5 plays, 75 yards, 2:27" ...
$ team :List of 217
$ drive_start :List of 217
$ drive_end :List of 217
$ timeElapsed :List of 217
$ yards : int [1:217] 75 75 75 75 75 75 12 12 12 12 ...
$ isScore : logi [1:217] TRUE TRUE TRUE TRUE TRUE TRUE ...
$ offensivePlays : int [1:217] 5 5 5 5 5 5 3 3 3 3 ...
$ result : chr [1:217] "TD" "TD" "TD" "TD" ...
$ shortDisplayResult: chr [1:217] "TD" "TD" "TD" "TD" ...
$ displayResult : chr [1:217] "Touchdown" "Touchdown" "Touchdown" "Touchdown" ...
$ plays :List of 217This gives us 188 plays, but plays is still a list column, so we need to “widen” it with unnest_wider(). Let’s go ahead and do that and then look at what the data looks like.
pbp_raw_espn_plays <- pbp_raw_espn %>%
unnest_longer(plays) %>%
unnest_wider(plays) %>%
rename(play_id = id)
pbp_raw_espn_plays %>%
glimpse()Rows: 217
Columns: 29
$ name <int> 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, …
$ drive_id <chr> "4012203031", "4012203031", "4012203031", "40122030…
$ description <chr> "5 plays, 75 yards, 2:27", "5 plays, 75 yards, 2:27…
$ team <list> ["Jaguars", "JAX", "Jacksonville Jaguars", "Jaguar…
$ drive_start <list> [["quarter", 1], ["15:00"], 75, "JAX 25"], [["quar…
$ drive_end <list> [["quarter", 1], ["12:33"], 0, "MIN 0"], [["quarte…
$ timeElapsed <list> ["2:27"], ["2:27"], ["2:27"], ["2:27"], ["2:27"], …
$ yards <int> 75, 75, 75, 75, 75, 75, 12, 12, 12, 12, 12, 12, 66,…
$ isScore <lgl> TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, FALSE, FALSE, F…
$ offensivePlays <int> 5, 5, 5, 5, 5, 5, 3, 3, 3, 3, 3, 3, 10, 10, 10, 10,…
$ result <chr> "TD", "TD", "TD", "TD", "TD", "TD", "PUNT", "PUNT",…
$ shortDisplayResult <chr> "TD", "TD", "TD", "TD", "TD", "TD", "PUNT", "PUNT",…
$ displayResult <chr> "Touchdown", "Touchdown", "Touchdown", "Touchdown",…
$ play_id <chr> "40122030340", "40122030355", "40122030379", "40122…
$ sequenceNumber <chr> "4000", "5500", "7900", "10800", "12900", "15000", …
$ type <list> ["53", "Kickoff", "K"], ["24", "Pass Reception", "…
$ text <chr> "D.Bailey kicks 65 yards from MIN 35 to end zone, T…
$ awayScore <int> 0, 0, 0, 0, 0, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, …
$ homeScore <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ period <list> [1], [1], [1], [1], [1], [1], [1], [1], [1], [1], …
$ clock <list> ["15:00"], ["15:00"], ["14:25"], ["13:54"], ["13:2…
$ scoringPlay <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, FAL…
$ priority <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FA…
$ modified <chr> "2020-12-06T22:12Z", "2020-12-06T22:12Z", "2020-12-…
$ wallclock <chr> "2020-12-06T18:02:32Z", "2020-12-06T18:03:13Z", "20…
$ start <list> [0, 0, 35, 65, ["16"]], [1, 10, 75, 75, "1st & 10 …
$ end <list> [1, 10, 75, 75, "1st & 10 at JAX 25", "1st & 10", …
$ statYardage <int> 0, 24, 8, 9, 6, 28, 25, 5, 0, 7, 0, 13, 4, 4, 6, 9,…
$ scoringType <list> <NULL>, <NULL>, <NULL>, <NULL>, <NULL>, ["touchdow…Hoist away!
Looking good! We still have some list-columns to work on though (team, period, clock, start). Let’s pull some selected items from those columns via hoist(). I’m going to start with a small example, and limit the columns shown so that we don’t get overwhelmed.
tibble [1 × 4] (S3: tbl_df/tbl/data.frame)
$ drive_id: chr "4012203031"
$ play_id : chr "40122030340"
$ yards : int 75
$ team :List of 1
..$ :List of 5
.. ..$ name : chr "Jaguars"
.. ..$ abbreviation : chr "JAX"
.. ..$ displayName : chr "Jacksonville Jaguars"
.. ..$ shortDisplayName: chr "Jaguars"
.. ..$ logos :List of 4This shows us that the team list column has 5 named list items within it (name, abbreviation, displayName, shortDisplayName, and another list of lists for logos).
hoist() takes several arguments, first a column to work on (.col), and then some new columns to create. Note that we’re using raw strings ("name") to pull named list elements from the list column or we could use a number to grab by position.
pbp_raw_espn_plays %>%
select(drive_id, play_id, yards, team) %>%
hoist(
.col = team,
pos_team = "name",
pos_abb = "abbreviation",
pos_full = "displayName",
pos_short = 4 # could also use "shortDisplayName"
)# A tibble: 217 × 8
drive_id play_id yards pos_team pos_abb pos_full pos_short team
<chr> <chr> <int> <chr> <chr> <chr> <chr> <list>
1 4012203031 40122030340 75 Jaguars JAX Jackson… Jaguars <named list>
2 4012203031 40122030355 75 Jaguars JAX Jackson… Jaguars <named list>
3 4012203031 40122030379 75 Jaguars JAX Jackson… Jaguars <named list>
4 4012203031 4012203031… 75 Jaguars JAX Jackson… Jaguars <named list>
5 4012203031 4012203031… 75 Jaguars JAX Jackson… Jaguars <named list>
6 4012203031 4012203031… 75 Jaguars JAX Jackson… Jaguars <named list>
7 4012203032 4012203031… 12 Vikings MIN Minneso… Vikings <named list>
8 4012203032 4012203032… 12 Vikings MIN Minneso… Vikings <named list>
9 4012203032 4012203032… 12 Vikings MIN Minneso… Vikings <named list>
10 4012203032 4012203032… 12 Vikings MIN Minneso… Vikings <named list>
# … with 207 more rowsOk, so hopefully that shows you how we can first find the list column elements, and then hoist() a select few of them by name/position. For the next section I’m just going to hoist() the ones I want and then save the dataframe. While there are some other list columns, I’m just going to drop them as I’m not interested in them right now.
espn_pbp_clean <- pbp_raw_espn_plays %>%
hoist(
.col = team,
pos_team = "name",
pos_abb = "abbreviation",
pos_full = "displayName",
pos_short = 4 # could also use "shortDisplayName"
) %>%
hoist(
type,
play_type_id = "id",
play_type = "text",
play_type_abb = "abbreviation"
) %>%
hoist(
period,
quarter = "number"
) %>%
hoist(
clock,
clock = "displayValue"
) %>%
janitor::clean_names() %>%
# drop remaining list columns
select(-where(is.list))Join the data
The next thing we have to do is join the Win Probability data with the play-by-play info! This is easy as we have a common key column with play_id.
espn_joined <- left_join(espn_pbp_clean, win_pct_df, by = "play_id")
espn_joined %>%
glimpse()Rows: 217
Columns: 31
$ name <int> 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3…
$ drive_id <chr> "4012203031", "4012203031", "4012203031", "401220…
$ description <chr> "5 plays, 75 yards, 2:27", "5 plays, 75 yards, 2:…
$ pos_team <chr> "Jaguars", "Jaguars", "Jaguars", "Jaguars", "Jagu…
$ pos_abb <chr> "JAX", "JAX", "JAX", "JAX", "JAX", "JAX", "MIN", …
$ pos_full <chr> "Jacksonville Jaguars", "Jacksonville Jaguars", "…
$ pos_short <chr> "Jaguars", "Jaguars", "Jaguars", "Jaguars", "Jagu…
$ yards <int> 75, 75, 75, 75, 75, 75, 12, 12, 12, 12, 12, 12, 6…
$ is_score <lgl> TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, FALSE, FALSE,…
$ offensive_plays <int> 5, 5, 5, 5, 5, 5, 3, 3, 3, 3, 3, 3, 10, 10, 10, 1…
$ result <chr> "TD", "TD", "TD", "TD", "TD", "TD", "PUNT", "PUNT…
$ short_display_result <chr> "TD", "TD", "TD", "TD", "TD", "TD", "PUNT", "PUNT…
$ display_result <chr> "Touchdown", "Touchdown", "Touchdown", "Touchdown…
$ play_id <chr> "40122030340", "40122030355", "40122030379", "401…
$ sequence_number <chr> "4000", "5500", "7900", "10800", "12900", "15000"…
$ play_type_id <chr> "53", "24", "24", "5", "5", "67", "12", "24", "3"…
$ play_type <chr> "Kickoff", "Pass Reception", "Pass Reception", "R…
$ play_type_abb <chr> "K", "REC", "REC", "RUSH", "RUSH", "TD", NA, "REC…
$ text <chr> "D.Bailey kicks 65 yards from MIN 35 to end zone,…
$ away_score <int> 0, 0, 0, 0, 0, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6…
$ home_score <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
$ quarter <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
$ scoring_play <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, F…
$ priority <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, …
$ modified <chr> "2020-12-06T22:12Z", "2020-12-06T22:12Z", "2020-1…
$ wallclock <chr> "2020-12-06T18:02:32Z", "2020-12-06T18:03:13Z", "…
$ stat_yardage <int> 0, 24, 8, 9, 6, 28, 25, 5, 0, 7, 0, 13, 4, 4, 6, …
$ row_id <int> 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 1…
$ tie_percentage <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
$ home_win_percentage <dbl> 0.828, 0.807, 0.796, 0.785, 0.777, 0.742, 0.741, …
$ seconds_left <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…Now there’s one more tricky point, which is that there isn’t a column that says “home” vs “away”.
ESPN’s JSON reports this simply by position, we can access this data, and will need to create a logical statement in order to assign home vs away.
List of 2
$ :List of 2
..$ team :List of 11
..$ statistics:List of 25
$ :List of 2
..$ team :List of 11
..$ statistics:List of 25From comparing the box scores and the JSON, the team listed first is always the away team. So for this game that means the Jaguars.
# 1st team == AWAY
raw_espn_json[["boxscore"]][["teams"]][[1]][["team"]][["abbreviation"]][1] "JAX"# 2nd team == HOME
raw_espn_json[["boxscore"]][["teams"]][[2]][["team"]][["abbreviation"]][1] "MIN"final_espn <- espn_joined %>%
mutate(
home_team = raw_espn_json[["boxscore"]][["teams"]][[1]][["team"]][["abbreviation"]],
away_team = raw_espn_json[["boxscore"]][["teams"]][[2]][["team"]][["abbreviation"]]
)Just for fun, let’s create a very quick graph to compare against the ESPN Win Percentage plot! Note that we still need to calculate the game seconds (from the clock data), so I’ll just use the row number as the x-axis for now. We can see that this aligns well with the “actual” plot from ESPN’s box score!
final_espn %>%
ggplot(aes(x = row_id, y = 1 - home_win_percentage)) +
geom_line(size = 1) +
scale_y_continuous(breaks = c(0, 0.25, .5, .75, 1), labels = c(100, "", 50, "", 100), limits = c(0, 1)) +
theme_minimal() +
theme(
panel.grid.minor = element_blank(),
panel.grid.major.x = element_blank(),
axis.text.y.right = element_text(size = 24),
axis.text.x = element_blank()
) +
labs(x = "", y = "")Warning: Removed 1 row(s) containing missing values (geom_path).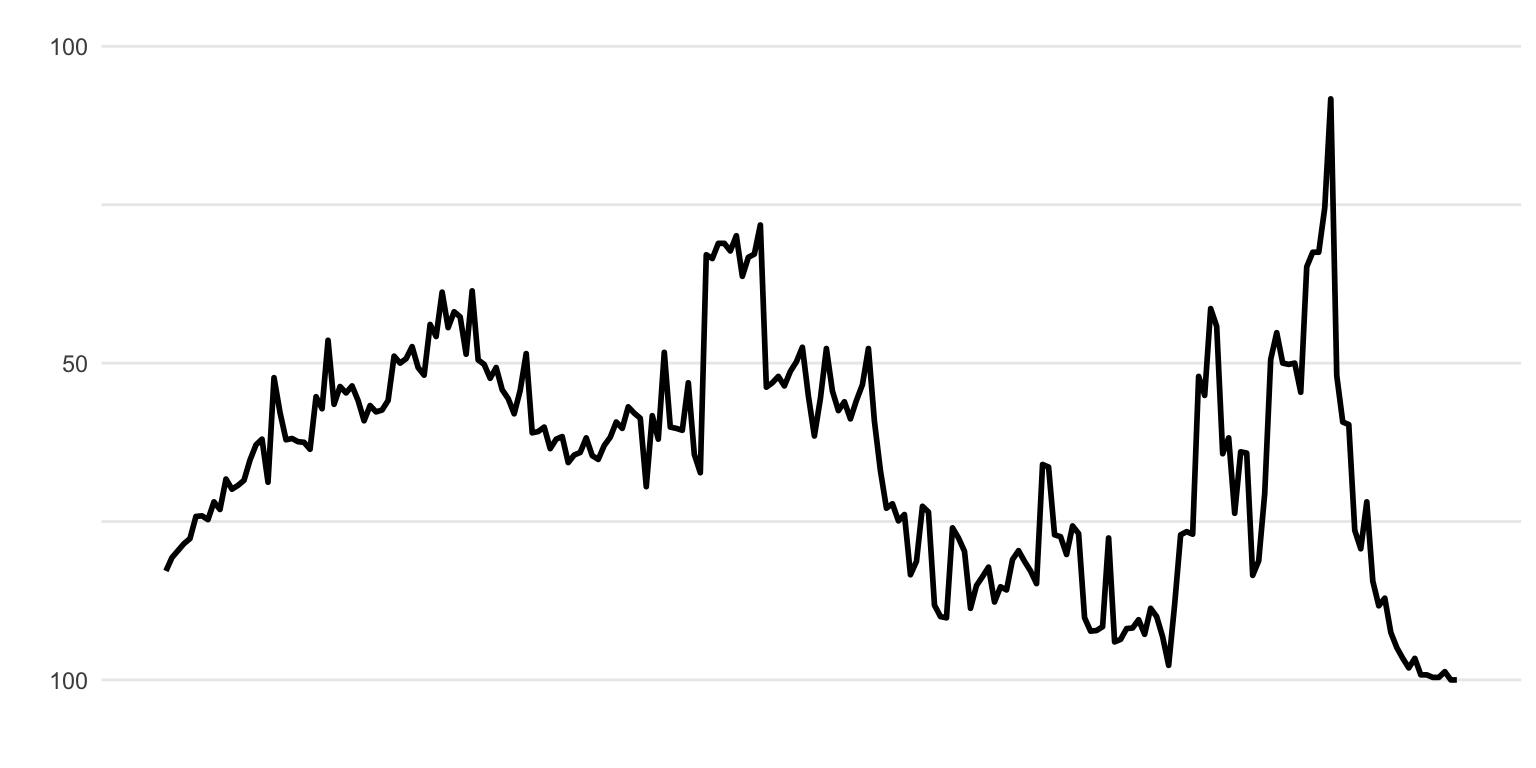
Roll it into a Function
We can quickly convert that into a function. Eventually this will be rolled into espnscrapeR proper. For now, I just have espnscrapeR::get_espn_win_prob().
get_espn_pbp <- function(game_id) {
espn_url <- glue::glue("http://site.api.espn.com/apis/site/v2/sports/football/nfl/summary?event={game_id}")
raw_espn_json <- fromJSON(espn_url, simplifyVector = FALSE)
win_pct_df <- raw_espn_json[["winprobability"]] %>%
enframe() %>%
rename(row_id = name) %>%
unnest_wider(value) %>%
janitor::clean_names()
espn_df <- raw_espn_json[["drives"]][[1]] %>%
enframe() %>%
unnest_wider(value) %>%
rename(
drive_id = id,
drive_start = start,
drive_end = end
) %>%
unnest_longer(plays) %>%
unnest_wider(plays)
pbp_raw_espn_plays <- pbp_raw_espn %>%
unnest_longer(plays) %>%
unnest_wider(plays) %>%
rename(play_id = id)
espn_pbp_clean <- pbp_raw_espn_plays %>%
hoist(
.col = team,
pos_team = "name",
pos_abb = "abbreviation",
pos_full = "displayName",
pos_short = 4 # could also use "shortDisplayName"
) %>%
hoist(
type,
play_type_id = "id",
play_type = "text",
play_type_abb = "abbreviation"
) %>%
hoist(
period,
quarter = "number"
) %>%
hoist(
clock,
clock = "displayValue"
) %>%
janitor::clean_names() %>%
# drop remaining list columns
select(-where(is.list))
espn_joined <- left_join(espn_pbp_clean, win_pct_df, by = "play_id")
final_espn <- espn_joined %>%
mutate(
home_team = raw_espn_json[["boxscore"]][["teams"]][[1]][["team"]][["abbreviation"]],
away_team = raw_espn_json[["boxscore"]][["teams"]][[2]][["team"]][["abbreviation"]]
)
final_espn
}
get_espn_pbp("401220303") %>% glimpse()Rows: 217
Columns: 33
$ name <int> 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3…
$ drive_id <chr> "4012203031", "4012203031", "4012203031", "401220…
$ description <chr> "5 plays, 75 yards, 2:27", "5 plays, 75 yards, 2:…
$ pos_team <chr> "Jaguars", "Jaguars", "Jaguars", "Jaguars", "Jagu…
$ pos_abb <chr> "JAX", "JAX", "JAX", "JAX", "JAX", "JAX", "MIN", …
$ pos_full <chr> "Jacksonville Jaguars", "Jacksonville Jaguars", "…
$ pos_short <chr> "Jaguars", "Jaguars", "Jaguars", "Jaguars", "Jagu…
$ yards <int> 75, 75, 75, 75, 75, 75, 12, 12, 12, 12, 12, 12, 6…
$ is_score <lgl> TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, FALSE, FALSE,…
$ offensive_plays <int> 5, 5, 5, 5, 5, 5, 3, 3, 3, 3, 3, 3, 10, 10, 10, 1…
$ result <chr> "TD", "TD", "TD", "TD", "TD", "TD", "PUNT", "PUNT…
$ short_display_result <chr> "TD", "TD", "TD", "TD", "TD", "TD", "PUNT", "PUNT…
$ display_result <chr> "Touchdown", "Touchdown", "Touchdown", "Touchdown…
$ play_id <chr> "40122030340", "40122030355", "40122030379", "401…
$ sequence_number <chr> "4000", "5500", "7900", "10800", "12900", "15000"…
$ play_type_id <chr> "53", "24", "24", "5", "5", "67", "12", "24", "3"…
$ play_type <chr> "Kickoff", "Pass Reception", "Pass Reception", "R…
$ play_type_abb <chr> "K", "REC", "REC", "RUSH", "RUSH", "TD", NA, "REC…
$ text <chr> "D.Bailey kicks 65 yards from MIN 35 to end zone,…
$ away_score <int> 0, 0, 0, 0, 0, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6…
$ home_score <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
$ quarter <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
$ scoring_play <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE, F…
$ priority <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, …
$ modified <chr> "2020-12-06T22:12Z", "2020-12-06T22:12Z", "2020-1…
$ wallclock <chr> "2020-12-06T18:02:32Z", "2020-12-06T18:03:13Z", "…
$ stat_yardage <int> 0, 24, 8, 9, 6, 28, 25, 5, 0, 7, 0, 13, 4, 4, 6, …
$ row_id <int> 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 1…
$ tie_percentage <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
$ home_win_percentage <dbl> 0.828, 0.807, 0.796, 0.785, 0.777, 0.742, 0.741, …
$ seconds_left <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
$ home_team <chr> "JAX", "JAX", "JAX", "JAX", "JAX", "JAX", "JAX", …
$ away_team <chr> "MIN", "MIN", "MIN", "MIN", "MIN", "MIN", "MIN", …More ESPN
Now you may be asking yourself, how the heck do I get the game_id to use with our fancy new function?!
ESPN provides the “scoreboard” for many sports, including the NFL, you can query it like so, which returns 333 games from 2018 for example. Note that this includes playoffs from the 2017 season (it is just returning any games that were played in the 2018 calendar year).
espn_scores_url <- "http://site.api.espn.com/apis/site/v2/sports/football/nfl/scoreboard?dates=2018&limit=500"
raw_json_scores <- httr::GET(espn_scores_url) %>%
httr::content()
raw_json_scores %>% str(max.level = 1)List of 2
$ leagues:List of 1
$ events :List of 333Looks like we’re interested in the events list element, so let’s take a look at the first few observations in it, and see what we’re working with.
List of 3
$ :List of 9
..$ id : chr "400999175"
..$ uid : chr "s:20~l:28~e:400999175"
..$ date : chr "2018-01-06T21:20Z"
..$ name : chr "Tennessee Titans at Kansas City Chiefs"
..$ shortName : chr "TEN @ KC"
..$ season :List of 3
..$ competitions:List of 1
..$ links :List of 5
..$ status :List of 4
$ :List of 9
..$ id : chr "400999171"
..$ uid : chr "s:20~l:28~e:400999171"
..$ date : chr "2018-01-07T01:15Z"
..$ name : chr "Atlanta Falcons at Los Angeles Rams"
..$ shortName : chr "ATL @ LAR"
..$ season :List of 3
..$ competitions:List of 1
..$ links :List of 3
..$ status :List of 4
$ :List of 9
..$ id : chr "400999176"
..$ uid : chr "s:20~l:28~e:400999176"
..$ date : chr "2018-01-07T18:05Z"
..$ name : chr "Buffalo Bills at Jacksonville Jaguars"
..$ shortName : chr "BUF @ JAX"
..$ season :List of 3
..$ competitions:List of 1
..$ links :List of 5
..$ status :List of 4Yep! That’s the one of interest, and we’ve got essentially a data.frame inside each of the list elements. So we can apply our typical workflow of enframe() + unnest_wider().
espn_games_2018 <- raw_json_scores[["events"]] %>%
enframe() %>%
rename(row_id = name) %>%
unnest_wider(value) %>%
rename(game_id = id)
espn_games_2018 %>%
glimpse()Rows: 333
Columns: 10
$ row_id <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17…
$ game_id <chr> "400999175", "400999171", "400999176", "400999177", "4009…
$ uid <chr> "s:20~l:28~e:400999175", "s:20~l:28~e:400999171", "s:20~l…
$ date <chr> "2018-01-06T21:20Z", "2018-01-07T01:15Z", "2018-01-07T18:…
$ name <chr> "Tennessee Titans at Kansas City Chiefs", "Atlanta Falcon…
$ shortName <chr> "TEN @ KC", "ATL @ LAR", "BUF @ JAX", "CAR @ NO", "ATL @ …
$ season <list> [2017, 3, "post-season"], [2017, 3, "post-season"], [201…
$ competitions <list> [["400999175", "s:20~l:28~e:400999175~c:400999175", "201…
$ links <list> [["en-US", ["summary", "desktop", "event"], "https://www…
$ status <list> [0, "0:00", 4, ["3", "STATUS_FINAL", "post", TRUE, "Fina…We still need to grab some information from the season column, and there are few other list-columns if we wanted to further clean the data.
tibble [1 × 1] (S3: tbl_df/tbl/data.frame)
$ competitions:List of 1
..$ :List of 19
.. ..$ id : chr "400999175"
.. ..$ uid : chr "s:20~l:28~e:400999175~c:400999175"
.. ..$ date : chr "2018-01-06T21:20Z"
.. ..$ attendance : int 73319
.. ..$ type :List of 2
.. .. ..$ id : chr "14"
.. .. ..$ abbreviation: chr "RD16"
.. ..$ timeValid : logi TRUE
.. ..$ neutralSite : logi FALSE
.. ..$ conferenceCompetition: logi FALSE
.. ..$ recent : logi FALSE
.. ..$ venue :List of 5
.. .. ..$ id : chr "3622"
.. .. ..$ fullName: chr "GEHA Field at Arrowhead Stadium"
.. .. ..$ address :List of 2
.. .. ..$ capacity: int 72936
.. .. ..$ indoor : logi FALSE
.. ..$ competitors :List of 2
.. .. ..$ :List of 11
.. .. ..$ :List of 11
.. ..$ notes :List of 1
.. .. ..$ :List of 2
.. ..$ status :List of 4
.. .. ..$ clock : num 0
.. .. ..$ displayClock: chr "0:00"
.. .. ..$ period : int 4
.. .. ..$ type :List of 7
.. ..$ broadcasts :List of 1
.. .. ..$ :List of 2
.. ..$ leaders :List of 3
.. .. ..$ :List of 5
.. .. ..$ :List of 5
.. .. ..$ :List of 5
.. ..$ format :List of 1
.. .. ..$ regulation:List of 1
.. ..$ startDate : chr "2018-01-06T21:20Z"
.. ..$ geoBroadcasts :List of 2
.. .. ..$ :List of 5
.. .. ..$ :List of 5
.. ..$ headlines :List of 1
.. .. ..$ :List of 3
hoist again
So we’re going to use hoist() to again grab specific items from our list columns. Here I’m passing increasing “depth” to hoist() via a list(). While it can be a bit hard to initially wrap your head around, hoist() is similar to native subsetting with R.
So the following code is roughly equivalent in base R and hoist(). Note that the subsetting base R version with [[ is getting the first element (of 333), so I’m going to grab the first element of our new home_team_id column from our vectorized hoist() call.
ex_id_subset <- espn_season_2018[["competitions"]][[1]][["competitors"]][[1]][["id"]]
ex_id_hoist <- espn_season_2018 %>%
hoist(competitions, home_team_id = list("competitors", 1, "id"))
all.equal(ex_id_subset, ex_id_hoist[["home_team_id"]][1])[1] TRUESo we can now use that same idea to grab a few desired columns. We can sanity check our work by seeing how many games we have of each “type” with a quick count(). There should be 256 regular season games in each season.
espn_season_2018_final <- espn_season_2018 %>%
hoist(
competitions,
home_team_id = list("competitors", 1, "id"),
home_team_abb = list("competitors", 1, "team", "abbreviation"),
away_team_id = list("competitors", 2, "id"),
away_team_abb = list("competitors", 2, "team", "abbreviation"),
home_score = list("competitors", 1, "score"),
away_score = list("competitors", 2, "score")
) %>%
select(-where(is.list), -row_id) %>%
janitor::clean_names() %>%
rename(season_type = type) %>%
mutate(
season_type = case_when(
season_type == 1L ~ "Preseason",
season_type == 2L ~ "Regular Season",
season_type == 3L ~ "Playoffs",
TRUE ~ as.character(season_type),
)
)
espn_season_2018_final %>%
count(season_type)# A tibble: 3 × 2
season_type n
<chr> <int>
1 Playoffs 12
2 Preseason 65
3 Regular Season 256We could then find a specific game or purrr::map() across all the games as needed.
Inside the below detail tag, we have the full method of getting the data as JSON, cleaning/rectangling, and returning as a relatively tidy dataframe.
ESPN Schedule Function
get_espn_schedule <- function(season) {
espn_scores_url <- glue::glue("http://site.api.espn.com/apis/site/v2/sports/football/nfl/scoreboard?dates={season}&limit=500")
raw_json_scores <- fromJSON(espn_scores_url, simplifyVector = FALSE)
espn_games <- raw_json_scores[["events"]] %>%
enframe() %>%
rename(row_id = name) %>%
unnest_wider(value) %>%
rename(game_id = id)
espn_season <- espn_games %>%
unnest_wider(season) %>%
unchop(competitions)
espn_season_final <- espn_season %>%
hoist(
competitions,
home_team_id = list("competitors", 1, "id"),
home_team_abb = list("competitors", 1, "team", "abbreviation"),
away_team_id = list("competitors", 2, "id"),
away_team_abb = list("competitors", 2, "team", "abbreviation"),
home_score = list("competitors", 1, "score"),
away_score = list("competitors", 2, "score")
) %>%
select(-where(is.list), -row_id) %>%
janitor::clean_names() %>%
rename(season_type = type) %>%
mutate(
season_type = case_when(
season_type == 1L ~ "Preseason",
season_type == 2L ~ "Regular Season",
season_type == 3L ~ "Playoffs",
TRUE ~ as.character(season_type),
)
)
espn_season_final
}
Expand for Session Info
─ Session info ───────────────────────────────────────────────────────────────
setting value
version R version 4.2.0 (2022-04-22)
os macOS Monterey 12.2.1
system aarch64, darwin20
ui X11
language (EN)
collate en_US.UTF-8
ctype en_US.UTF-8
tz America/Chicago
date 2022-04-28
pandoc 2.18 @ /Applications/RStudio.app/Contents/MacOS/quarto/bin/tools/ (via rmarkdown)
quarto 0.9.294 @ /usr/local/bin/quarto
─ Packages ───────────────────────────────────────────────────────────────────
package * version date (UTC) lib source
dplyr * 1.0.8 2022-02-08 [1] CRAN (R 4.2.0)
forcats * 0.5.1 2021-01-27 [1] CRAN (R 4.2.0)
ggplot2 * 3.3.5 2021-06-25 [1] CRAN (R 4.2.0)
jsonlite * 1.8.0 2022-02-22 [1] CRAN (R 4.2.0)
purrr * 0.3.4 2020-04-17 [1] CRAN (R 4.2.0)
reactable * 0.2.3 2020-10-04 [1] CRAN (R 4.2.0)
readr * 2.1.2 2022-01-30 [1] CRAN (R 4.2.0)
rvest * 1.0.2 2021-10-16 [1] CRAN (R 4.2.0)
sessioninfo * 1.2.2 2021-12-06 [1] CRAN (R 4.2.0)
stringr * 1.4.0 2019-02-10 [1] CRAN (R 4.2.0)
tibble * 3.1.6 2021-11-07 [1] CRAN (R 4.2.0)
tidyr * 1.2.0 2022-02-01 [1] CRAN (R 4.2.0)
tidyverse * 1.3.1 2021-04-15 [1] CRAN (R 4.2.0)
xml2 * 1.3.3 2021-11-30 [1] CRAN (R 4.2.0)
[1] /Library/Frameworks/R.framework/Versions/4.2-arm64/Resources/library
──────────────────────────────────────────────────────────────────────────────