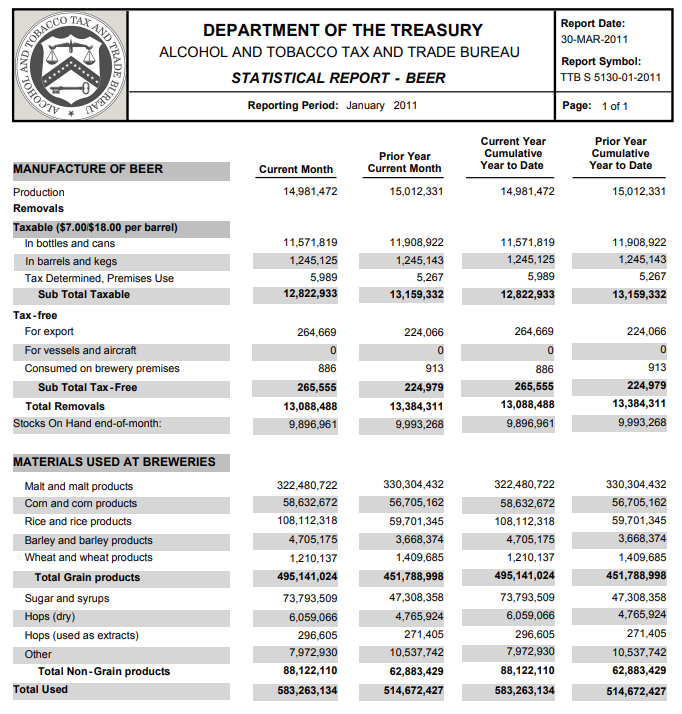
[1] " Report Date:\n DEPARTMENT OF THE TREASURY 30-MAR-2011\n ALCOHOL AND TOBACCO TAX AND TRADE BUREAU\n Report Symbol:\n STATISTICAL REPORT - BEER TTB S 5130-01-2011\n\n Reporting Period: January 2011 Page: 1 of 1\n\n\n Current Year Prior Year\n Prior Year Cumulative Cumulative\nMANUFACTURE OF BEER Current Month Current Month Year to Date Year to Date\n\nProduction 14,981,472 15,012,331 14,981,472 15,012,331\nRemovals\nTaxable ($7.00/$18.00 per barrel)\n In bottles and cans 11,571,819 11,908,922 11,571,819 11,908,922\n In barrels and kegs 1,245,125 1,245,143 1,245,125 1,245,143\n Tax Determined, Premises Use 5,989 5,267 5,989 5,267\n Sub Total Taxable 12,822,933 13,159,332 12,822,933 13,159,332\nTax-free\n For export 264,669 224,066 264,669 224,066\n For vessels and aircraft 0 0 0 0\n Consumed on brewery premises 886 913 886 913\n Sub Total Tax-Free 265,555 224,979 265,555 224,979\n Total Removals 13,088,488 13,384,311 13,088,488 13,384,311\nStocks On Hand end-of-month: 9,896,961 9,993,268 9,896,961 9,993,268\n\n\nMATERIALS USED AT BREWERIES\n\n Malt and malt products 322,480,722 330,304,432 322,480,722 330,304,432\n Corn and corn products 58,632,672 56,705,162 58,632,672 56,705,162\n Rice and rice products 108,112,318 59,701,345 108,112,318 59,701,345\n Barley and barley products 4,705,175 3,668,374 4,705,175 3,668,374\n Wheat and wheat products 1,210,137 1,409,685 1,210,137 1,409,685\n Total Grain products 495,141,024 451,788,998 495,141,024 451,788,998\n\n Sugar and syrups 73,793,509 47,308,358 73,793,509 47,308,358\n Hops (dry) 6,059,066 4,765,924 6,059,066 4,765,924\n Hops (used as extracts) 296,605 271,405 296,605 271,405\n Other 7,972,930 10,537,742 7,972,930 10,537,742\n Total Non-Grain products 88,122,110 62,883,429 88,122,110 62,883,429\nTotal Used 583,263,134 514,672,427 583,263,134 514,672,427\n\n\n 296,605 Pounds of hops is equivalent to 212,541 pounds of extract JAN 2011\n 271,405 Pounds of hops is equivalent to 101,087 pounds of extract JAN 2010\n\n\n\n\nNOTE: Changes in figures from prior reports could be due to amended reports being filed.\n This data is not final and may need to be amended.\n\n\n\nhttp://www.ttb.gov\n"